Le problème est de connecter par un réseau (de câbles) un ensemble de
points ; on connaît les distances entre tous les couples de points entre
lesquels on peut installer un câble, et on veut minimiser la longueur
totale du câble qui doit être utilisé. On modélise le problème par un
graphe non orienté
![]() ,
muni d'une fonction de coût
,
muni d'une fonction de coût
![]() .
Une solution du problème est un sous-graphe
.
Une solution du problème est un sous-graphe
![]() connexe sans circuit, c'est-à-dire un arbre, de
coût minimum, ce coût étant
connexe sans circuit, c'est-à-dire un arbre, de
coût minimum, ce coût étant
![]() ;
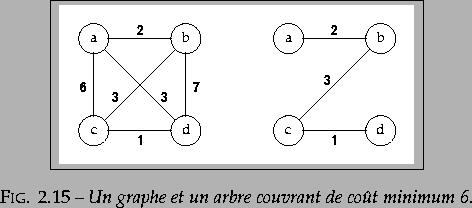
une telle solution est appelée un arbre couvrant de coût
minimum (voir figure 2.15). On
suppose que le problème a une solution, c'est-à-dire que le graphe
;
une telle solution est appelée un arbre couvrant de coût
minimum (voir figure 2.15). On
suppose que le problème a une solution, c'est-à-dire que le graphe
![]() est connexe. Il existe plusieurs algorithmes pour
résoudre ce problème. Ce sont des algorithmes gloutons qui construisent
la solution de façon incrémentale en ajoutant une arête à chaque étape.
est connexe. Il existe plusieurs algorithmes pour
résoudre ce problème. Ce sont des algorithmes gloutons qui construisent
la solution de façon incrémentale en ajoutant une arête à chaque étape.
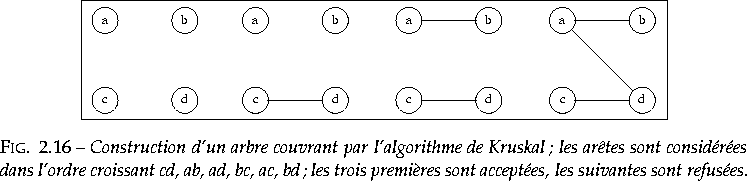
L'algorithme de
Kruskal (1956) utilise une forêt
![]() (c'est-à-dire un ensemble d'arbres disjoints). Initialement, la forêt
est formée de tous les sommets du graphe, sans aucune arête. À chaque
étape, on ajoute à la forêt une arête choisie de coût minimum, mais
seulement si cette arête ne crée pas de circuit. Pour cela, on range
d'abord les arêtes par ordre de coût croissant et on les considère dans
cet ordre ; une arête dont les deux extrémités appartiennent au même
arbre de
(c'est-à-dire un ensemble d'arbres disjoints). Initialement, la forêt
est formée de tous les sommets du graphe, sans aucune arête. À chaque
étape, on ajoute à la forêt une arête choisie de coût minimum, mais
seulement si cette arête ne crée pas de circuit. Pour cela, on range
d'abord les arêtes par ordre de coût croissant et on les considère dans
cet ordre ; une arête dont les deux extrémités appartiennent au même
arbre de
![]() est refusée et ne sera plus considérée ; une
arête qui relie deux arbres
est refusée et ne sera plus considérée ; une
arête qui relie deux arbres
![]() de
de
![]() est
acceptée, elle est ajoutée à
est
acceptée, elle est ajoutée à
![]() ,
ce qui a pour effet de
joindre les arbres a1 et a2. L'arbre couvrant est cosntruit quand
toutes les arêtes ont été examinées (figure 2.16).
,
ce qui a pour effet de
joindre les arbres a1 et a2. L'arbre couvrant est cosntruit quand
toutes les arêtes ont été examinées (figure 2.16).
Pour s'assurer que l'on ne crée pas de circuit, c'est-à-dire que l'arête
choisie relie deux arbres distincts de
![]() ,
on gère une
structure de données de partition (ou
d'ensembles disjoints ). En effet, la
forêt
,
on gère une
structure de données de partition (ou
d'ensembles disjoints ). En effet, la
forêt
![]() détermine une partition de l'ensemble S des
sommets : S est réunion disjointe des ensembles de sommets de chaque
arbre de
détermine une partition de l'ensemble S des
sommets : S est réunion disjointe des ensembles de sommets de chaque
arbre de
![]() .
Les trois opérations de cette structure de
données sont : initialiser, représenter, fusionner. L'initialiser
consiste à créer une partition de S consistant en |S|sous-ensembles, chacun à un élément ; représenter() associe à
tous les éléments d'un sous-ensemble un même objet de sorte que des
objets appartenant à des sous-ensembles distincts soient représentés par
des objets distincts ; on peut alors déterminer si deux éléments de Sappartiennent au même sous-ensemble en comparant leurs représentants ;
fusionner() consiste à remplacer deux sous-ensembles par leur
réunion.
.
Les trois opérations de cette structure de
données sont : initialiser, représenter, fusionner. L'initialiser
consiste à créer une partition de S consistant en |S|sous-ensembles, chacun à un élément ; représenter() associe à
tous les éléments d'un sous-ensemble un même objet de sorte que des
objets appartenant à des sous-ensembles distincts soient représentés par
des objets distincts ; on peut alors déterminer si deux éléments de Sappartiennent au même sous-ensemble en comparant leurs représentants ;
fusionner() consiste à remplacer deux sous-ensembles par leur
réunion.
interface Partition {
Object représenter(int i);
void fusionner(int i, int j);
}
Une implémentation de cette interface est réalisée par la classe
PartitionParArborescences, à l'aide d'arborescences dont les
sommets comportent un lien qui pointe vers le parent (contrairement aux
arbres binaires où les liens pointent vers les enfants), la racine de
chaque arborescence pointant vers elle-même. Les sommets de ces
arborescences sont décrits par la classe membre Arborescence.
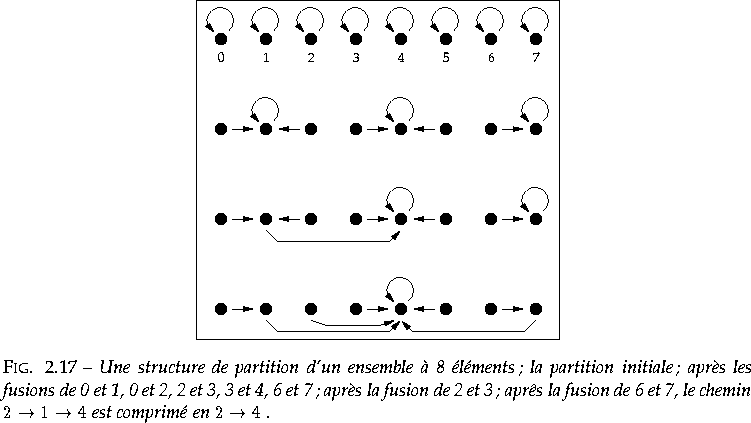
Dans l'opération fusionner(), on peut choisir de faire de la
racine du plus petit des deux arbres un enfant du plus grand ; un champ
rang est utilisé à cet effet. On peut aussi profiter de chaque
opération représenter() pour comprimer le chemin menant
d'un élément à la racine en faisant de tous les sommets sur ce chemin
des enfants de la racine (figure 2.17). On peut montrer
que la complexité d'une suite de m opérations est
![]() où
où
![]() est une fonction très lentement croissante et en pratique
majorée par 4 (c'est un résultat de Tarjan qui date de 1975). Grâce à
cette implémentation, la complexité de l'algorithme de Kruskal est en
est une fonction très lentement croissante et en pratique
majorée par 4 (c'est un résultat de Tarjan qui date de 1975). Grâce à
cette implémentation, la complexité de l'algorithme de Kruskal est en
![]() .
.
class PartitionParArborescences implements Partition {
Arborescence[] t;
// PartitionParArborescences(Set s) { ... }
public Object représenter(int i) {
return représenter(t[i]);
}
Arborescence représenter(Arborescence a) {
if (a.parent != a) {
a.parent = représenter(a.parent);
}
return a.parent;
}
public void fusionner(int i, int j) {
relier(représenter(t[i]), représenter(t[j]));
}
void relier(Arborescence a, Arborescence b) {
if (a.rang > b.rang)
b.parent = a;
else {
a.parent = b;
if (a.rang == b.rang) b.rang++;
}
}
static class Arborescence {
Arborescence parent;
Object étiquette;
int rang;
Arborescence(Object étiquette) {
this.parent = this;
this.étiquette = étiquette;
}
}
}
L'algorithme de Prim (1957) construit incrémentalement un arbre en ajoutant à chaque étape une arête, choisie de coût minimum. Initialement, l'arbre est formé d'un unique sommet r, quelconque, du graphe.
L'algorithme utilise comme structure de données une file de priorité contenant à chaque étape tous les sommets qui n'appartiennent pas (encore) à l'arbre. Une file de priorité est une structure de données abstraite avec les opérations insérer(), minimum() et extraireMin(), et les objets insérés doivent implémenter l'interface Comparable :
interface FilePriorite {
void insérer(Object o);
Object minimum();
Object extraireMin();
}
Une file de priorité peut être implémentée par un tas-min
(Williams 1964), arbre binaire presque complet (tous les niveaux de
l'arbre sont remplis, sauf peut-être le niveau plus bas, dont les
n![]() uds sont tassés à gauche) ayant la propriété d'ordre suivante : un
n
uds sont tassés à gauche) ayant la propriété d'ordre suivante : un
n![]() ud est inférieur ou égal à ses enfants.
ud est inférieur ou égal à ses enfants.
Chaque sommet du graphe inséré dans le tas-min est affecté d'un entier
val qui est le coût minimum d'une arête reliant ce sommet à un
sommet de l'arbre courant et d'un lien parent vers un sommet de
l'arbre courant qui réalise ce minimum ; pour un sommet qui n'est pas
reliable par une arête à l'arbre courant, l'entier val vaut
![]() et parent vaut null. Initialement, le
tas-min est formé de tous les sommets, val étant
et parent vaut null. Initialement, le
tas-min est formé de tous les sommets, val étant ![]() ,
sauf
pour r, val étant 0 et parent étant null.
Ensuite, tant que le tas-min est non vide, on en retire un sommet avec
val minimum ; soit x ce sommet, qui appartiendra désormais à
l'arbre couvrant ; pour chaque sommet y adjacent à x, si y est
dans le tas-min et si
c(x,y) < y.val, alors on met à jour
val et on fait de x le parent de y, en exécutant les
affectations
y.parent = x et
y.val = c(x,y). La
complexité de cet algorithme dépend de l'implémentation du tas-min ; on
sait réaliser l'opération extraireMin() en un temps
,
sauf
pour r, val étant 0 et parent étant null.
Ensuite, tant que le tas-min est non vide, on en retire un sommet avec
val minimum ; soit x ce sommet, qui appartiendra désormais à
l'arbre couvrant ; pour chaque sommet y adjacent à x, si y est
dans le tas-min et si
c(x,y) < y.val, alors on met à jour
val et on fait de x le parent de y, en exécutant les
affectations
y.parent = x et
y.val = c(x,y). La
complexité de cet algorithme dépend de l'implémentation du tas-min ; on
sait réaliser l'opération extraireMin() en un temps
![]() .
L'algorithme de Prim peut donc être implémenté en
.
L'algorithme de Prim peut donc être implémenté en
![]() .
.
La construction d'un arbre couvrant de poids minimum a bien d'autres applications. Par exemple, les sommets du graphe peuvent représenter des données (mots, images, plantes, etc.), une arête ayant un coût mesurant une notion de proximité entre ces données (entre deux mots, deux images, deux plantes, etc.). On veut répartir ces données en deux classes telles que deux données de la même classe soient plus proches que deux données de deux classes différentes, et obtenir une classification en itérant ce partage (comme en botanique). On commence par construire un arbre couvrant de poids minimum de ce graphe ; on sélectionne une arête de plus grand coût dans cet arbre ; cette arête relie deux sous-arbres, dont les ensembles de sommets constituent les deux classes cherchées, au premier niveau de la classification. On itère ensuite la sélection d'une arête de plus grand coût dans les deux sous-arbres pour avoir les niveaux successifs de la classification.