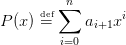
Soit P(x) un polynôme de degré n :
On cherche ici à évaluer la valeur du polynôme pour une valeur donnée y. Pour ce faire, on peut factoriser le polynôme P(x) sous la forme :
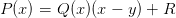 | (1) |
où Q(x) est un polynôme de degré n− 1 et R une constante scalaire. Sous cette forme on voit que P(y) = R et que P′(y) = Q(y). Le polynôme Q(x) est bien sur différent du polynôme P′(x) mais leur valeurs coïncident quand x prends la valeur y.
Soit bi les coefficients du polynôme Q :
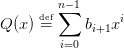 | (2) |
en développant l’équation (1) on obtient facilement une équation récurrente permettant de calculer les coefficients du polynôme Q :
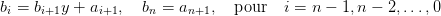 | (3) |
La valeur de R est donnée par b0. On notera que l’on peut initialiser la récurrence par bn = an+1 ou quitte à rajouter un point par bn+1 = 0.
Cet Algorithme s’appelle algorithme d’Horner, il revient à évaluer la valeur du polynôme P en le factorisant sous la forme :
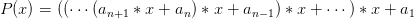
Nous avons noté que la dérivée de P(x) au point y s’obtient en évaluant Q(y). Il suffit donc de réappliquer l’algorithme d’Horner au polynôme Q pour évaluer P′(y).
Question 1 Écrire une fonction [Q,R]=Horner(P,xi) qui calcule la décomposition (Q,R) du polynôme P. Tester le code en utilisant les primitives Scilab horner et derivat.
En fait, on peut calculer directement les valeurs P(y) et P′(y) sans passer par l’intermédiaire de la construction du polynôme Q, c’est à dire sans stocker les coefficients du polynôme Q. On écrit conjointement les deux algorithmes de Horner et pour faciliter la gestion des indices on initialise le deuxième avec cn = 0 plutôt que cn−1 = bn. Ainsi les deux vecteurs de coefficients à calculer auront même taille :
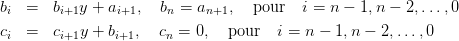
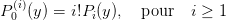 | (4) |
et d’obtenir ainsi les dérivées successives de P en y.
Question 2 Écrire une fonction [val]=Hornerp(P,xi,p) qui calcule 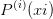 pour
pour
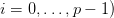 et renvoit les valeurs calculées dans le vecteur val. On pourra à nouveau
tester le code en utilisant les primitives Scilab horner et derivat.
et renvoit les valeurs calculées dans le vecteur val. On pourra à nouveau
tester le code en utilisant les primitives Scilab horner et derivat.
Supposons que l’on ait estimé un zéro ξ du polynôme P, dans la décomposition de P(x) = Q(x)(x−ξ) + R on doit avoir R = 0 et la méthode de Horner permet d’éliminer la racine ξ du polynôme P(x) puisqu’elle donne les coefficients du polynôme Q. Mais si ξ est une racine de P(x) on doit aussi avoir R = b0 = 0 dans l’algorithme de Horner.
On peut donc utiliser la récurrence (3) à partir de de bn = an+1 (méthode forward) ou à partir de b0 = 0 méthode backward. Si l’on cherche à éliminer successivement les racines d’un polynôme en éliminant à chaque fois la plus grande racine, la méthode backward donne une meilleur stabilité numérique.
On peut comparer les deux méthodes avec le polynôme P(x)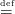 ∏
j=013(x− 2−j) en utilisant la
fonction roots de Scilab pour estimer les valeurs des racines.
∏
j=013(x− 2−j) en utilisant la
fonction roots de Scilab pour estimer les valeurs des racines.
Question 3 Écrire les deux fonctions [Q]=deflate_forward(P,xi) [Q]=deflate_backward
et les utiliser pour factoriser le polynôme 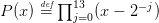 en évaluant à chaque fois
la plus grande racine d’un polynôme à l’aide de la fonction Scilab roots.
en évaluant à chaque fois
la plus grande racine d’un polynôme à l’aide de la fonction Scilab roots.
L’équation (3) permettant de calculer les coefficients du polynôme Q peut-être vu comme un système dynamique discret. La stabilité de ce système ou de celui obtenu pour le calcul simultané de P et de ses dérivées au point y dépend de |y|. Pour |y| > 1 le système est instable et on va donc pour des polynômes de grande taille amplifier les erreurs de calcul si l’on utilise (3). Mais on peut remarquer que P(x) s’écrit aussi :
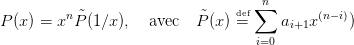 | (5) |
Pour une valeur de y telle que |y| > 1. on se ramène à un système dynamique stable en utilisant
l’algorithme de Horner pour l’évaluation de 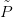 et de ses dérivées en 1∕y et on utilise la relation (5)
pour les relier aux valeurs de P et de ses dérivées en y.
et de ses dérivées en 1∕y et on utilise la relation (5)
pour les relier aux valeurs de P et de ses dérivées en y.
Question 4 Écrire l’algorithme de Horner backward pour estimer la valeur d’un polynôme et de sa dérivée première en un point y. Comparer les deux algorithmes.
On utilise ici la méthode de Newton pour trouver les zéros d’un polynôme. Soit P(x) un polynôme de degré n, on utilise pour trouver les zéros l’algorithme de Newton qui consiste à effectuer les itérations suivantes :
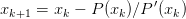 | (6) |
Il faut pouvoir évaluer la valeur du polynôme et de sa dérivée au point courant xk et nous avons vu qu’un algorithme d’Horner permet d’évaluer ces deux quantités.
La convergence de l’algorithme de Newton dans ce cas particulier est donnée par le théorème suivant :
Théorème 1 Soit P un polynôme de degré n dont toutes les racines sont réelles. La méthode de Newton donne une suite strictement décroissante pour x0 > ξ1 où xi1 est la plus grande racine de P.
On trouvera la preuve de la convergence dans [? ]. Pour implémenter cet algorithme il faut trouver un majorant de ξ1. Plusieurs formules de majoration sont données dans la littérature. Par exemple :
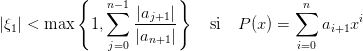 | (7) |
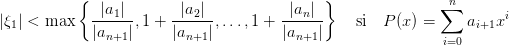 | (8) |
Question 5 Programmer l’algorithme de Newton et le tester sur le polynôme :
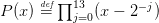
En éliminant à chaque fois la plus grande racine trouvée on peut chercher toutes les racines du polynôme P(x). On peut constater dans le code qui suit que la méthode d’élimination choisie (forward ou backward) n’est pas anodine !
Question 6 Programmer la recherche de toutes les racines
du polynôme : 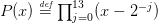 en utilisant l’algorithme de Newton et les méthodes
d’élimination [Q]=deflate_forward(P,xi) et [Q]=deflate_backward. Comparer les résultats
en utilisant l’algorithme de Newton et les méthodes
d’élimination [Q]=deflate_forward(P,xi) et [Q]=deflate_backward. Comparer les résultats
Plutôt que d’essayer de simplifier le polynôme P on peut utiliser la méthode de Maehly (1954) qui consiste à appliquer la méthode de Newton à la fraction rationnelle P(x)∕(x − ξ) plutôt que d’éliminer la racine ξ du polynôme P(x). Ainsi si l’on a estimé les j premières racines du polynôme, notées ξi, on cherche la j + 1-ème racine par l’algorithme de Newton :
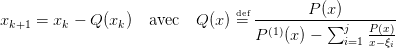 | (9) |
Pour initialiser l’algorithme, on peut utiliser la dernière racine trouvée (à epsilon près pour éviter une division par zéro).
Question 7 Programmer la recherche de toutes les racines du polynôme :
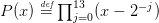 en utilisant l’algorithme de Maehly.
en utilisant l’algorithme de Maehly.