Didier CHAUVEAU - Jean-François DELMAS
Date: dernière date de mise à jour : 19 novembre 2003
Il existe deux types de nuages qui donnent lieu à des précipitations: les nuages chauds et les nuages froids. Ces derniers possèdent une température maximale de l'ordre de -10°C à -25°C. Ils sont composés de cristaux de glace et de gouttelettes d'eau. Ces gouttelettes d'eau subsistent alors que la température ambiante est inférieure à la température de fusion. On parle d'eau surfondue. Leur état est instable. De fait, quand une particule de glace rencontre une gouttelette d'eau, elles s'aggrègent pour ne former qu'une seule particule de glace. Les particules de glace, plus lourdes que les gouttelettes, tombent sous l'action de la gravité. Enfin si les températures des couches d'air inférieures sont suffisamment élevées, les particules de glace fondent au cours de leur chute formant ainsi de la pluie.
En l'absence d'un nombre suffisant de cristaux de glace pour initier le phénomène décrit ci-dessus, on peut injecter dans le nuage froid des particules qui ont une structure cristalline proche de la glace, par exemple de l'iodure d'argent (environ 100 à 1000 grammes par nuage). Autour de ces particules, on observe la formation de cristaux de glace, ce qui permet, on l'espère, de déclencher ou d'augmenter les précipitations. Il s'agit de l'ensemencement des nuages. Signalons que cette méthode est également utilisée pour limiter le risque de grêle.
Il est évident que la possibilité de modifier ainsi les précipitations présente un grand intérêt pour l'agriculture. De nombreuses études ont été et sont encore consacrées à l'étude de l'efficacité de l'ensemencement des nuages dans divers pays. L'étude de cette efficacité est cruciale et délicate. Le débat est encore d'actualité.
Les volumes de pluie déversées en
![]() m
m![]() (cf. les deux tableaux ci-dessous)
concernent 23 jours similaires dont
(cf. les deux tableaux ci-dessous)
concernent 23 jours similaires dont ![]() jours avec
ensemencement correspondant aux réalisations des variables aléatoires
jours avec
ensemencement correspondant aux réalisations des variables aléatoires
![]() et
et ![]() jours sans
ensemencement correspondant aux réalisations des variables aléatoires
jours sans
ensemencement correspondant aux réalisations des variables aléatoires
![]() .
.
|
|
X=[7.45, 4.70, 7.30, 4.05, 4.46, 9.70, 15.10, 8.51, 8.13, 2.20, 2.16]; Y=[15.53, 10.39, 4.50, 3.44, 5.70, 8.24, 6.73, 6.21, 7.58, 4.17, 1.09, 3.50]; n1 = length(X); n2 = length(Y);
On suppose que les volumes de pluies suivent une loi gaussienne et que l'effet de l'ensemencement ne modifie pas la variance des loies gaussiennes.
Ceci revient à dire dans ce contexte paramétrique que les observations
sont constituées de deux échantillons gaussiens indépendants
| i.i.d. | |||
| i.i.d. |
Nous admettons donc dans un premier temps ces deux hypothèses.
Afin de se faire une idée des données et de l'écart entre les deux populations, on peut commencer par calculer les moyennes empiriques
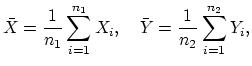
![$\displaystyle \mathop{\frac{1}{ n_1-1}}\nolimits \sum_{i=1}^{n_1} (X_i-\bar X)^...
..._1-1}\left[
\frac{1}{n_1} \sum_{i=1}^{n_1} X_i^2 -
\left(\bar X\right)^2\right]$](img22.png) |
|||
![$\displaystyle \frac{1}{n_2-1}\sum_{i=1}^{n_2} (Y_i-\bar Y)^2
= \frac{n_2}{ n_2-1}\left[
\frac{1}{n_2} \sum_{i=1}^{n_2} Y_i^2 -
\left(\bar Y\right)^2\right],$](img24.png) |
// calcul des moyennes mu1=sum(X)/n1 mu2=sum(Y)/n2 // calcul des variances empiriques sans biais SX2 = n1/(n1-1)*(sum(X.^2)/n1- mu1^2) SY2 = n2/(n2-1)*(sum(Y.^2)/n2- mu2^2)
Question 1
Quelles sont les lois des v.a.
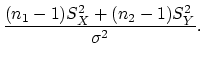
|
Question 2
En déduire que sous
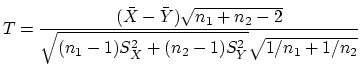
|
Question 3
Construire, à
partir de la statistique
|
On donne les commandes Scilab suivantes concernant la fonction de répartion (``cumulative distribution function'' en anglais) de la loi de Student:
c = cdft("T",k,p,1-p) donne à
[p,q] = cdft("PQ",t,k) donne à
cdft, on peut
consulter le manuel en utilisant la commande help cdft.
Pour s'assurer du point (2), on peut tout d'abord supposer que
ces variances sont différentes, i.e.
Question 4 (Facultatif)
Quelle est la loi de la statistique
|
Question 5 (Facultatif)
Construire, à partir de la statistique
|
On donne les commandes Scilab suivantes concernant la fonction de répartion de la loi de Fisher:
c = cdff("F",k1,k2,p,1-p) donne à
[p,q] = cdff("PQ",f,k1,k2) donne à
cdff, on peut
consulter le manuel en utilisant la commande help cdff.
On dispose de données (réelles) relatives à 6 jeux de notes pour un même contrôle, corrigé par un unique correcteur, mais concernant six petites classes (et donc six enseignants) différentes. On désire savoir si les résultats des petites classes sont significativement différents.
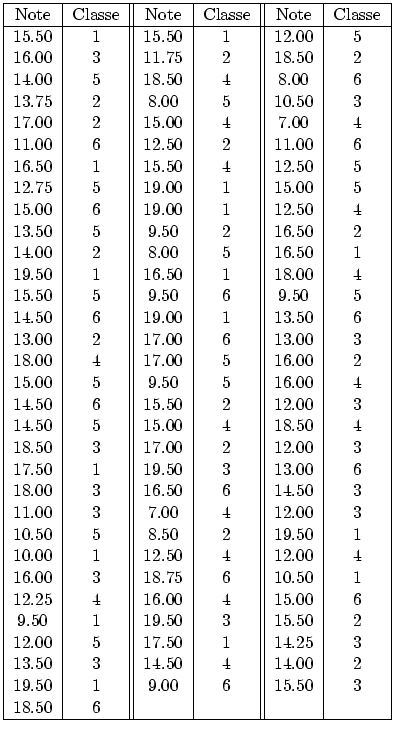
Question 6
Quelles sont les estimations des
|
// données notes X=[ 15.50; 15.50; 12.00; 16.00; 11.75; 18.50; 14.00; 18.50; 8.00; 13.75; 8.00; 10.50; 17.00; 15.00; 7.00; 11.00; 12.50; 11.00; 16.50; 15.50; 12.50; 12.75; 19.00; 15.00; 15.00; 19.00; 12.50; 13.50; 9.50; 16.50; 14.00; 8.00; 16.50; 19.50; 16.50; 18.00; 15.50; 9.50; 9.50; 14.50; 19.00; 13.50; 13.00; 17.00; 13.00; 18.00; 17.00; 16.00; 15.00; 9.50; 16.00; 14.50; 15.50; 12.00; 14.50; 15.00; 18.50; 18.50; 17.00; 12.00; 17.50; 19.50; 13.00; 18.00; 16.50; 14.50; 11.00; 7.00; 12.00; 10.50; 8.50; 19.50; 10.00; 12.50; 12.00; 16.00; 18.75; 10.50; 12.25; 16.00; 15.00; 9.50; 19.50; 15.50; 12.00; 17.50; 14.25; 13.50; 14.50; 14.00; 19.50; 9.00; 15.50; 18.50]; // données facteur Grp=[ 1; 1; 5; 3; 2; 2; 5; 4; 6; 2; 5; 3; 2; 4; 4; 6; 2; 6; 1; 4; 5; 5; 1; 5; 6; 1; 4; 5; 2; 2; 2; 5; 1; 1; 1; 4; 5; 6; 5; 6; 1; 6; 2; 6; 3; 4; 5; 2; 5; 5; 4; 6; 2; 3; 5; 4; 4; 3; 2; 3; 1; 3; 6; 3; 6; 3; 3; 4; 3; 5; 2; 1; 1; 4; 4; 3; 6; 1; 4; 4; 6; 1; 3; 2; 5; 1; 3; 3; 4; 2; 1; 6; 3; 6]; N = length(X); k = max(Grp); // nb de groupes mg = sum(X)/N; // X.. for i=1:k, n(i) = length(X(Grp==i)); end; // n_i for i=1:k, moy(i) = sum(X(Grp==i))/n(i); end; // X_i. [n,moy] // effectif et moyenne de chaque groupe
Question 7
Peut-on considérer qu'il existe une différence significative entre les
notes des classes, dues aux qualités pédagogiques des enseignants?
Effectuer le test de l'hypothèse nulle
|
On pourra utiliser les commandes suivantes:
// calcul des sommes de carres SSM = sum(n.*(moy-mg).^2); SSE = sum((X-moy(Grp)).^2);
Question 8 (Facultatif)
Si l'on rejette
|

Si l'on veut étudier la liaison entre les variables potentiellement
explicatives et la variable à expliquer (le prix ![]() ), on peut
commencer par visualiser les nuages de points
), on peut
commencer par visualiser les nuages de points ![]() et
et ![]() :
:
clear donnees = [ 5 92 7.8; 4 64 9.5; 6 124 6.4; 5 97 7.5; 5 79 8.1; 5 76 9.0; 6 93 6.1; 6 63 8.7; 2 13 15.4; 7 111 6.4; 7 143 4.4]; // definition des variables X1=donnees(:,1); X2=donnees(:,2); Y=donnees(:,3); n=length(Y); // allures des nuages xbasc(); subplot(121), plot2d(X1,Y,-2,"111","Age",[1,0,8,16]); subplot(122), plot2d(X2,Y,-3,"111","Kms",[0,0,150,16]);
Question 9
Que suggèrent les deux nuages?
|
On propose tout d'abord le modèle
Question 10
Donner des estimateurs sans biais pour les paramètres
|
On propose ici de définir une fonction qui, à partir de la
donnée du modèle sous la forme
![]() , où
, où ![]() est la
variable à expliquer et
est la
variable à expliquer et ![]() la matrice définissant le modèle, calcule
les éléments usuels: L'estimateur du paramètre
la matrice définissant le modèle, calcule
les éléments usuels: L'estimateur du paramètre ![]() :
:
Dans le cas de ce premier modèle à 1 régresseur, la réponse à la
question 7 est donc directement donnée par cette fonction, puisque ici
elle effectue le test de
![]() contre
contre
![]() .
.
function [theta,MSE,pv] = regression(M,Y)
// regression lineaire avec table d'anova
// M = matrice (n,p) des regresseurs, Y = observations (n,1)
// theta = estimateur des parametres
// MSE = Mean Square Error estimateur de la variance
// pv = p-valeur du test de Ho : "pas de regresseurs"
[n,p]=size(M);
theta = inv(M'*M)*M'*Y; // estimateur des parametres
// calcul des sommes de carres
YE = M*theta; // projete sur E
SSE = sum((Y - YE).^2); // ||Y-YE||^2
MSE = SSE/(n-p);
SSM = sum((YE - mean(Y)).^2); // ||YE-YH||^2
MSM = SSM/(p-1);
F = MSM/MSE; // Fisher
q5 = cdff("F",p-1,n-p,0.95,0.05); // quantile a 5%
[pp,qq] = cdff("PQ",F,p-1,n-p);
pv=qq; // p-valeur
// Affichage de la table d'anova
printf("\n");
printf("TABLE D''ANALYSE DE LA VARIANCE\n");
printf("Source SS DF MS Fisher p-valeur\n");
printf("-----------------------------------------------\n");
printf("Model %6.1f %3d %6.1f %4.1f %f\n",...
SSM,p-1,MSM,F,pv);
printf("Error %6.1f %3d %6.1f\n",SSE,n-p,MSE);
printf("-----------------------------------------------\n");
printf("quantile de F(%d,%d) a 95%% : %f\n",p-1,n-p,q5);
endfunction;
Le calcul donne pour notre modèle:
// MODELE 1 (simple) Y = b + a X1 + eps
M1 = [ones(n,1) X1]; // matrice des regresseurs
[theta1,MSE1,pv1] = regression(M1,Y);
printf("Estimateurs: b=%f, a=%f\n",theta1(1),theta1(2));
printf("Variance = %f, sigma = %f\n",MSE1,sqrt(MSE1));
On représente enfin la droite de régression sur le nuage:
xbasc(); // trace de la droite z=1:0.1:8; t=theta1(1)+theta1(2)*z; xbasc(); plot2d(X1,Y,-2,"111","Age",[1,0,8,16]); plot2d(z,t,[1],"000");
On propose d'essayer à présent le modèle ``complet''
Question 11
Donner des estimations sans biais des paramètres
|
Question 12
Test de l'utilité d'un régresseur:
Tester, au niveau 5%, l'hypothèse nulle
``le kilométrage n'a pas d'effet sur le prix'' contre ``c'est faux''.
|
La fonction définie précédemment n'effectue pas le test demandé
(quel test effectue-t-elle?). Ecrire les commandes Scilab permettant
de calculer la statistique et la ![]() -valeur du test demandé, et
conclure.
-valeur du test demandé, et
conclure.
Question 13
Quel modèle explique le mieux le prix?
|