L'algorithme opère sur une forêt , c'est-à-dire une
ensemble d'arbres. Ceux-ci sont des arbres étiquetés
complets : tout n![]() ud interne (c'est-à-dire qui
n'est pas une feuille) a deux fils non-vides (l'arbre de la
figure 22 n'est pas complet car les n
ud interne (c'est-à-dire qui
n'est pas une feuille) a deux fils non-vides (l'arbre de la
figure 22 n'est pas complet car les n![]() uds 4 et 7 n'ont
qu'un seul fils non-vide).
uds 4 et 7 n'ont
qu'un seul fils non-vide).
La forêt initiale est formée d'un arbre à un n![]() ud pour chaque lettre
du langage-source, dont l'étiquette est la probabilité de cette lettre.
La forêt finale est formée d'un unique arbre, qui est l'arbre de
décodage du code.
ud pour chaque lettre
du langage-source, dont l'étiquette est la probabilité de cette lettre.
La forêt finale est formée d'un unique arbre, qui est l'arbre de
décodage du code.
L'algorithme est de type glouton : il
choisit à chaque étape les deux arbres d'étiquettes minimales, soit ![]() et
et
![]() , et les remplace par l'arbre formé de
, et les remplace par l'arbre formé de ![]() et
et ![]() et ayant
comme étiquette la somme de l'étiquette de
et ayant
comme étiquette la somme de l'étiquette de ![]() et de l'étiquette de
et de l'étiquette de ![]() .
.
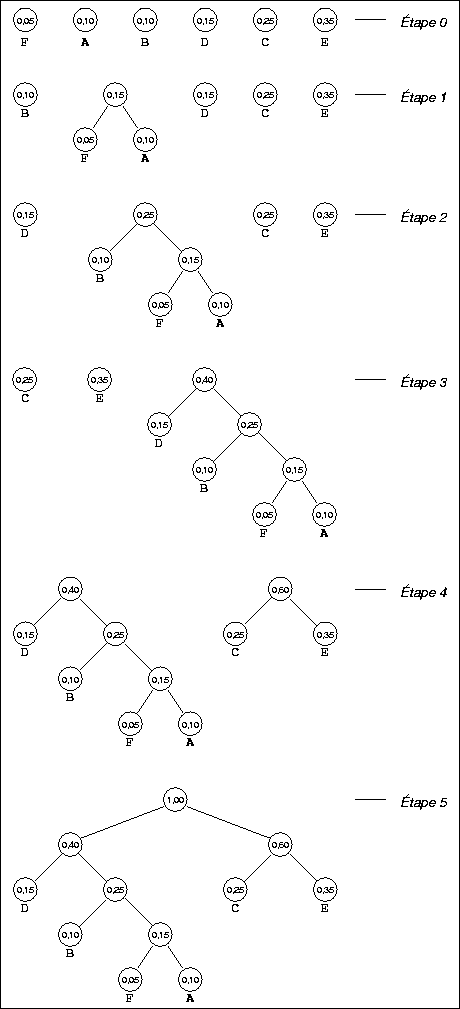
La figure ![[*]](cross_ref_motif.gif) représente les étapes de la construction d'un
code de Huffman pour l'alphabet source
représente les étapes de la construction d'un
code de Huffman pour l'alphabet source ![]() , avec les
probabilités
, avec les
probabilités ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
,![]() ,
, ![]() .
.
Le code d'une lettre est alors déterminé en suivant le chemin depuis la racine de l'arbre jusqu'à la feuille associée à cette lettre en concaténant successivement un 0 ou un 1 selon que la branche suivie est à gauche ou à droite. Le codage se réalise facilement à l'aide d'une table associant à chaque lettre son code :
Une fois ce code construit, le décodage se réalise avec un arbre
de décodage (figure 7, page ), grâce à
la propriété de préfixe des codes de Huffman (voir § 24).
Compte tenu de ces probabilités, le code obtenu a une longueur moyenne
de ![]() , alors que l'entropie du langage source est
, alors que l'entropie du langage source est ![]() , qui est
légèrement inférieure. On montre que la longueur moyenne d'un code de
Huffman peut approcher l'entropie d'aussi près que voulu, à condition de
coder non pas des lettres, mais des blocs de lettres de longueur assez
grande.
, qui est
légèrement inférieure. On montre que la longueur moyenne d'un code de
Huffman peut approcher l'entropie d'aussi près que voulu, à condition de
coder non pas des lettres, mais des blocs de lettres de longueur assez
grande.