Les systèmes de traitement de l'information ont toujours utilisé des techniques de codage, bien avant l'informatique : les différents systèmes d'écriture, le Braille, le Morse, la sténo. Avec la généralisation de la numérisation de l'information sous toutes ses formes, il existe maintenant une grande variété de codes, adaptés à ses divers supports de transmission et de stockage (cables coaxiaux, ondes hertziennes, disques magnétiques, CD-ROM, DCC, etc). Les codes sont conçus, outre la simple représentation de l'information, pour satisfaire à certaines exigences sur l'information codée : réduire sa taille (c'est la compression de données), la rendre incompréhensible par des tiers (c'est la cryptographie), permettre de reconstituer l'information initiale, même si elle a été altérée par un bruit (c'est la correction d'erreurs). Le schéma général est indiqué par la figure 6.
Les codes les plus simples sont de longueur constante. Le plus connu
est le code ASCII, qui
représente chaque caractère par un mot (ou suite) de 7 bits et permet
ainsi de représenter des textes quelconques, des sources de C++ aux romans
de Faulkner10.
L'alphabet de la source est constitué des 128 (![]() )
caractères représentables : les 26 lettres de l'alphabet latin, en
minuscules et en majuscules, les 10 chiffres, les signes de ponctuation
et symboles usuels (
)
caractères représentables : les 26 lettres de l'alphabet latin, en
minuscules et en majuscules, les 10 chiffres, les signes de ponctuation
et symboles usuels (<, &, @, etc) et des symboles
spéciaux. L'alphabet du code est ![]() et sa longueur est 7. Par
exemple, le caractère A est codé par le mot 1000001.
Les types entiers et flottants de C++ sont également représentés à l'aide
de codes de longueur constante.
et sa longueur est 7. Par
exemple, le caractère A est codé par le mot 1000001.
Les types entiers et flottants de C++ sont également représentés à l'aide
de codes de longueur constante.
Il existe aussi des codes de longueur variable, qui représentent les
lettres les plus fréquentes par des mots courts. C'est le cas du Morse,
qui code la lettre E, la plus fréquente, par
un `.' et la lettre Y, plus rare, par `-.--'. Une
propriété importante est l'unicité du décodage, problème qui ne se pose
pas pour les codes de longueur constante. Il peut être résolu pour des
codes de longueur variable, mais de façon trop coûteuse, quand un
symbole spécial sépare deux mots successifs du code (le blanc dans le
cas du Morse). On peut ne pas recourir à cette technique quand un code
est préfixe, c'est-à-dire si aucun mot du
code n'est le préfixe d'un autre mot du code (par exemple 01
étant préfixe de 0111, ces deux mots ne peuvent appartenir à un
code préfixe).
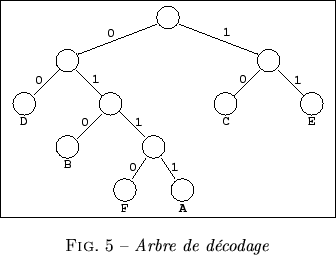
Le décodage d'un code préfixe se fait à l'aide d'un arbre, comme celui de la figure 7. Il suffit de lire les symboles successifs du texte codé : si c'est un 0, on suit la branche de gauche, si c'est un 1, celle de droite ; quand on arrive à une feuille de l'arbre, on a décodé une lettre de la source ; on remonte alors à la racine et on continue avec le symbole binaire suivant. Ainsi, 010011110 se décode en BAC, sans qu'il soit nécessaire de le décomposer a priori en 010 0111 10.