
| L'École des Ponts ParisTech est membre fondateur de |
L'École des Ponts ParisTech est certifiée |



|
|


Chacun sait que l’eau gèle en dessous de 0°C. Ce que l’on sait moins c’est que la phase liquide peut exister en-dessous de cette limite. Quand elle reste liquide en dessous de 0°C on dit que l’eau est surfondue. Ainsi les nuages sont presque toujours constitués de gouttelettes d’eau surfondue coexistant avec quelques cristaux de glace. C’est un état d’équilibre instable et tout apport supplémentaire de cristaux de glace ou d’iodure d’argent provoque l’évaporation rapide des gouttelettes en surfusion. La vapeur ainsi libérée va aussitôt se solidifier sur les cristaux de glace qui grossissent et précipitent vers le sol en se réchauffant. En effet, aux températures négatives, l’air atmosphérique est saturé de vapeur d’eau par rapport à la glace avant de l’être par rapport à l’eau surfondue. C’est cette propriété qui est exploitée pour forcer les précipitations. Ces pluies artificiellement provoquées peuvent être intéressantes pour l’agriculture comme en témoignent les nombreuses expériences d’ensemencement réalisées dans le monde au cours des années 1950 à 1970. C’est ainsi qu’entre le 1er juin et le 23 août 1975 (83 jours), une expérience visant à accroître le volume des précipitations s’est tenue en Floride (USA). Les données suivantes sont extraites de l’article de W.L. Woodley, J. Simpson, R. Biondini et J. Berkeley (1977) : Rainfall Results 1970-75 : Florida Area Cumulus Experiment, publié dans Science, vol. 195, pp. 735-742.
Données d’ensemencement de nuages par iodure d’argent
| Expérience i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| Date Ti | 0 | 1 | 3 | 4 | 6 | 9 | 18 | 25 |
| Ensemencement Ei | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 |
| Pluies Zi | 12.85 | 5.52 | 6.29 | 6.11 | 2.45 | 3.61 | 0.47 | 4.56 |
| Expérience i | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| Date Ti | 27 | 8 | 29 | 32 | 33 | 35 | 38 | 39 |
| Ensemencement Ei | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 0 |
| Pluies Zi | 6.35 | 5.06 | 2.76 | 4.05 | 5.74 | 4.84 | 11.86 | 4.45 |
| Expérience i | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| Date Ti | 53 | 55 | 56 | 59 | 65 | 68 | 82 | 83 |
| Ensemencement Ei | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0 |
| Pluies Zi | 3.66 | 4.22 | 1.16 | 5.45 | 2.02 | 0.82 | 1.09 | 0.28 |
Les sentiments mitigés des agriculteurs peuvent se résumer ainsi :
Question 1 Qu’attendent les paysans du statisticien?
Les paragraphes qui suivent ont pour but de fournir la réponse du statisticien à l’aide d’une approche non-paramétrique (voir le livre de J. Bernier, E. Parent, JJ. Boreux, 2000, Stat pour l’environnement, Tec et Doc, où cet exemple est traité dans un cadre paramétrique).
On note X1,…,Xn1 les hauteurs de pluies avec ensemencement, et Y 1,…,Y n2 les hauteurs de pluies sans ensemencement.
On suppose que les variables aléatoires Y 1,…,Y n2 sont indépendantes et de même fonction de répartition F. On suppose que les variables aléatoires X1,…,Xn1 sont indépendantes et de même fonction de répartition FΔ = F(⋅− Δ). Le but est donc de tester l’hypothèse H′0 = {Δ ≤ 0}, ou plus exactement H0 = {Δ = 0}, contre son alternative H1 = {Δ > 0}. Remarquons que l’on ne fait pas d’hypothèse sur la loi de Y i. Il existe beaucoup de tests pour ce genre de problème. On se propose d’utiliser le test de Mann et Whitney (1947) qui repose sur les rangs de l’échantillon X dans l’échantillon des deux populations (X,Y ).
On définit
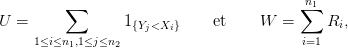
où Ri est le rang de Xi dans le réordonnement croissant de la population totale (X,Y ). On rappelle la relation entre W et U :
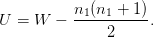
De plus les lois sous H0 de U et W ne dépendent pas de la fonction de répartition F.
Question 2 Quelles sont les valeurs maximales et minimales de W et U.
Sous H0, la loi de (R1,…,Rn1) est la loi de (σ1,…,σn1), où la permutation aléatoire σ = (σ1,…,σn1,σn1+1,…,σn1+n2) suit la loi uniforme sur l’ensemble des permutations de {1,…,n1 + n2}.
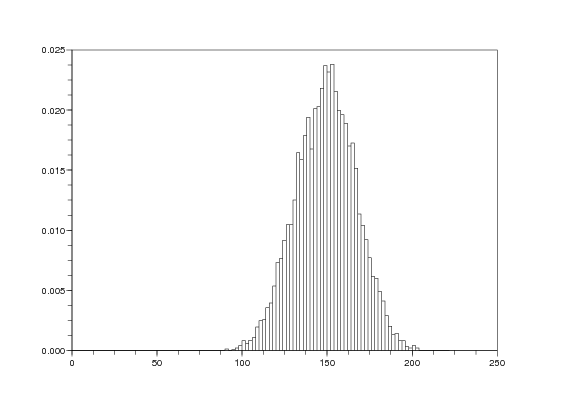
Il existe des tables pour la loi de W. Toutefois, il est aussi rapide d’en donner une approximation par simulation. On peut par exemple donner une estimation de ℙ(W > w) à l’aide de simulations de N variables aléatoires indépendantes de loi W. On commence par simuler la loi de W :
On fait N = 10000 simulations de W, W=simulation_loi_W(n1,n2,10000);, et on trace un histogramme (graphique 1) des valeurs obtenues pour visualiser une approximation de la loi de W :
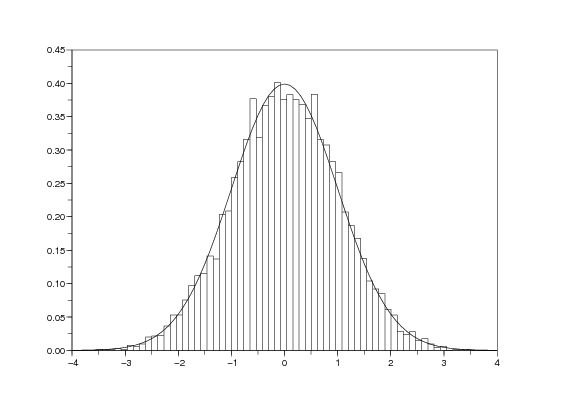
De même on simule la loi de U en se basant sur la relation entre U et W :
On rappelle que sous H0, on a
![1- -1-
𝔼 [U ] = 2 n1n2 et V ar(U ) = 12 n1n2 (n1 + n2 + 1 ).](test-de-comparaison3x.png)
De plus :
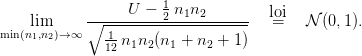
On trace la densité gaussienne sur l’histogramme de l’approximation de la loi de U afin de visualiser la convergence en loi ci-dessus. Pour obtenir le graphique 2, on utilise la fonction Scilab
avec par exemple N = 10000 simulations de U.
Sous H1, en revanche, les variables aléatoires Xi prennent en moyenne des valeurs plus grandes que les variables aléatoires Y i. Bien que la loi de U sous H1 ne soit pas accessible, car elle dépend de F, on remarque que W prend en moyenne des valeurs plus grandes sous H1 que sous H0. En particulier, on peut montrer que sous H1
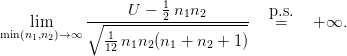
Question 3 Construire un test convergent à partir de la statistique U pour tester H0 contre H1. Déterminer la région critique associée à ce test de niveau α = 5%. On utilisera l’approche asymptotique et l’approche directe. Dans ce dernier cas, comme la fonction de répartition de U n’est pas explicite, on utilisera la fonction cdfUX qui fournit par simulation les quantiles de la loi de U.
Voici la fonction qui calcule par simulation les quantiles de la loi de U :
Question 4 Calculer la p-valeur associée au test précédent pour les données du problème, à l’aide de la fonction Scilab ci-dessous cdfU. Conclusion.
Question 5 Calculer la p-valeur pour les données du problème, à l’aide de l’approximation gaussienne. Conclusion.
Remarquons que ne pas rejeter H0 ne signifie pas que H0 soit vraie. Ainsi si on considère H′0 = {Δ ≤ 0}, au lieu de H0, on obtient la même région critique pour la statistique de test U. En particulier on ne peut pas distinguer H0 de H0′ et en fait même H0 de H0′′ = {ℙ(X1 ≥ x) ≤ ℙ(Y 1 ≥ x) ∀x ∈ ℝ} ou de H0′′′ = {ℙ(X1 ≤ Y 1) ≤ 1∕2}.
On suppose que les volumes de pluies suivent une loi gaussienne et que l’effet de l’ensemencement ne modifie pas la variance des lois gaussiennes.
Ceci revient à dire dans ce contexte paramétrique que les observations sont constituées de deux échantillons gaussiens indépendants
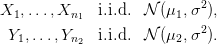
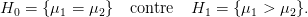
Il est indispensable de s’assurer d’abord que les hypothèses de modèle que l’on a faites sont raisonnables:
On peut répondre au point 1. à l’aide du test de Kolmogorov quand la moyenne et la variance sont connues a priori. Sinon, plusieurs tests de normalité sont détaillés dans la littérature. Le point 2. est abordé dans le paragraphe facultatif 3.2.
Nous admettons donc dans un premier temps ces deux hypothèses.
Afin de se faire une idée des données et de l’écart entre les deux populations, on peut commencer par calculer les moyennes empiriques
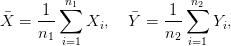
![∑n1 [ n∑1 ]
S2 = ---1--- (X − X¯)2 = --n1--- 1-- X2 − (X¯)2 ,
X n1 − 1 i n1 − 1 n1 i
i=n1 [ i=n1 ]
2 ---1---∑ 2 ¯ 2 --n2--- -1-∑ 2 2 (¯ )2
SY = n − 1 (Yi − Y ) = n − 1 n Y i − Y .
2 i=1 2 2 i=1](test-de-comparaison10x.png)
On rappelle que les variables aléatoires (resp. ) et (n1 − 1)SX2∕σ2 (resp. (n
2 − 1)SY 2∕σ2)
sont indépendantes et de loi 𝒩(μ1,σ2∕n
1) (resp. 𝒩(μ2,σ2∕n
2)) et χ2(n
1 − 1) (resp. χ2(n
2 − 1)).
Comme SX2 et S
Y 2 sont indépendants, on en déduit que la loi de 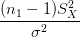 +
+ 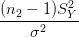 est la
loi du χ2 à n
1 + n2 − 2 degrés de liberté.
est la
loi du χ2 à n
1 + n2 − 2 degrés de liberté.
Sous H0, la loi de 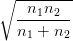
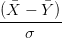 est la loi gaussienne centrée réduite. On en déduit que
sous H0,
est la loi gaussienne centrée réduite. On en déduit que
sous H0,
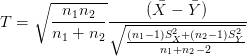
suit une loi de Student de paramètre n1 + n2 − 2.
Comme sous H1, − converge p.s. vers μ1 − μ2 > 0 quand min(n1,n2) →∞, et que
lim min(n1,n2)→∞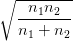 = +∞, on en déduit que sous H1, la statistique T diverge vers +∞
quand min(n1,n2) →∞.
= +∞, on en déduit que sous H1, la statistique T diverge vers +∞
quand min(n1,n2) →∞.
La fonction ttest2 ([Tobs,vc,pval]=ttest2(n1,Xbar,SX2,n2,Ybar,SY2,alpha)) retourne la valeur de la statistique T observée, Tobs, la valeur critique associée au niveau α, vc, et la p-valeur, pval, du test suggéré dans la question précédente. Cliquer sur le lien ci-dessus pour obtenir le code de la fonction, le sauvegarder, sous le nom ttest2.sce, dans le répertoire où vous utilisez scilab. Pour charger la fonction, utiliser la commande: getf 'ttest2.sce'. Pour appliquer la fonction, utiliser la commande:
ttest2(n1,Xbar,SX2,n2,Ybar,SY2,alpha)
On donne quelques indications pour la compréhension du code Scilab de ttest2 qui utilise la fonction de répartion (“cumulative distribution function” en anglais) de la loi de Student:
Pour avoir plus d’information sur la fonction cdft, on peut consulter le manuel en utilisant la commande help cdft.
Le but de ce qui suit est d’observer les résultats du tests quand les valeurs observées ou la taille de l’échantillon varient.
Question 8
Pour s’assurer du point (2), on peut tout d’abord supposer que ces variances sont différentes, i.e.
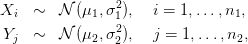
Question 10 (Facultatif) Quelle est la loi de la statistique F = SX2∕S Y 2 sous l’hypothèse nulle d’égalité des variances? Quel est son comportement sous H1, quand n1 →∞ et n2 →∞?
Question 11 (Facultatif) Construire, à partir de la statistique F, un test d’égalité des variances. Déterminer la région critique du test, évaluer la valeur critique au niveau α = 5% et la p-valeur pour les données de pluie? Conclusion.
On donne les commandes Scilab suivantes concernant la fonction de répartion de la loi de Fisher:
Pour avoir plus d’information sur la fonction cdff, on peut consulter le manuel en utilisant la commande help cdff.
Ce test est une variante du test de Kolmogorov Smirnov pour deux échantillons indépendants.
On dispose aussi dans ce cas d’un test de Kolmogorov Smirnov. Il s’agit de comparer les fonctions de répartition empirique
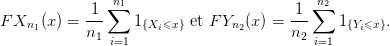
On définit la statistique du test
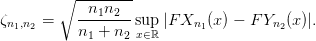
Utilisation de ce résultat :
La fonction ks2 ([D,q]=ks2(X,Y)) permet de réaliser le test précédemment décrit. Pour utiliser cette fonction, cliquer sur le lien ci-dessus et enregistrer el fichier sous le nom ks2.sce dans le répertoire dans lequel vous travaillez. Pour charger la fonction, utiliser la commande : exec 'ks2.sce'.
Explications des paramètres :
Cette fonction renvoie :
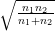
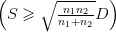 = ℙ(S ≥ ζn1,n2).
= ℙ(S ≥ ζn1,n2).
Question 12 Le procédé d’ensemencement proposé change-t-il significativement la loi des hauteurs de pluie?
| L'École des Ponts ParisTech est membre fondateur de |
L'École des Ponts ParisTech est certifiée |
|
|
|



