

| L'École des Ponts ParisTech est membre fondateur de |
L'École des Ponts ParisTech est certifiée |



|
|

N.B. : Tous les graphiques présentant l'effectif d'un parc sont en milliers de véhicules. Par
ailleurs, tous les graphiques montrant la répartition cumulée en types de véhicules présentent
de bas en haut le nombre de diesel inférieurs, diesel supérieurs, essences inférieurs, essences
moyens, essences supérieurs.
Introduction
L'objet de cette étude est de modéliser l'évolution du parc automobile à l'horizon 2020, d'une part dans son ensemble, mais surtout d'autre part dans sa répartition en classes d'âge et en classes technologiques. Une telle approche permet en effet de rendre compte du viellissement du parc, ainsi que de l'évolution de la part de chaque classe technologique dans le parc automobile de 2000 à 2020. Toutes ces données peuvent permettre par exemple de modéliser la pollution future, domaine où connaître la répartition du parc selon le type de carburant et l'âge des véhicules est primordial.
Nous allons donc tout au long de ce document voir pas à pas comment réaliser une telle étude à l'aide du logiciel Scilab, tant pour le calcul des différentes composantes du parc année après année que pour la visualisation des divers résultats obtenus. Ce qui nous permettra donc d'aborder à la fois les problèmes de modélisation des systèmes dynamiques sous Scilab et les problèmes de représentation graphique (courbes 3D, superposition de courbes 2D, etc...).
Notons enfin que toutes les données numériques sont tirées des ouvrages cités en bibliographie. Nous ne nous étendrons pas sur les problèmes de recensement des véhicules, le lecteur curieux pouvant se reporter aux dits ouvrages. Quant aux prévisions d'immatriculation, elles correspondent toutes aux projections à l'horizon 2020 du parc automobile français (limité aux seuls véhicules particuliers).
Mise en équation du problème
Avant d'aborder l'utilisation de Scilab à proprement parler, détaillons la manière de modéliser le parc automobile français sous forme d'un système dynamique.
Pour modéliser notre parc, nous allons répartir les véhicules en 28 classes d'âge. Chaque classe d'âge recouvre une année complète, et l'on suppose qu'aucune voiture ne survit après la 28ème classe1 .
Nous scindons par ailleurs le parc automobile en cinq classes technologiques :
Ces classes sont dénommées einf, eint, esup, dinf et dsup dans le programme écrit sous Scilab.
Comme nous l'avons signalé en introduction, nous scindons le parc en différentes classes technologiques car la finalité de notre étude est d'estimer les émissions polluantes dans le futur, ainsi que l'effet de nouvelles normes sur les dites émissions. Connaître la répartition en tranches d'âge mais aussi en type de motorisation et en cylindrée est donc important.
Chacune des classes technologiques que nous venons d'introduire est ensuite considérée comme un parc à part entière et simulée indépendamment des autres. Cela est possible puisqu'un véhicule ne passe jamais d'une classe technologique à une autre au cours de son existence.
Il ne reste ensuite qu'à sommer toutes les classes technologiques pour avoir l'évolution du parc automobile global. Cette approche peut paraître plus lourde en calculs qu'une approche globale, mais la légèreté des calculs nous permet d'en augmenter sans aucun problème la taille, et une telle approche permet d'avoir des informations sur l'âge des différents véhicules dans chaque classe technologique, d'où des résultats plus pertinents au final.
Chaque classe d'âge j d'une catégorie technologique i va vieillir d'un an à un certain taux qi,j(t), appelé taux de survie, et mourir (donc disparaître du parc) à un taux 1 − qi,j(t). Ce taux dépend du temps, même s'il sera pris constant dans le temps dans la majeure partie de cette étude2 . Par ailleurs, chaque année, on enregistre un nombre d'immatriculations neuves fi(t).
Cette modélisation n'est pas sans rappeler les modélisations d'évolutions des populations humaines, animales ou végétales, en remplaçant les immatriculations par les naissances. L'appellation taux de survie prend alors tout son sens.
En notant Ni(t) le vecteur colonne de 28 lignes correspondant à la population de la classe technologique i au temps t, et en prenant pour t des valeurs discrètes (t correspond à une année, et ne prend donc que des valeurs entières), on peut écrire l'équation d'évolution suivante :
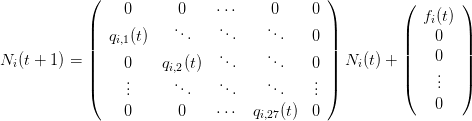 | (1) |
ce qui peut encore s'écrire, en nommant les deux matrices détaillées ci-dessus Mi(t) et Fi(t) :
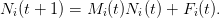 | (2) |
La mise en équation étant effectuée, nous allons à présent pouvoir aborder l'écriture de ce système sous Scilab.
Implémentation et initialisation du parc automobile sous Scilab
L'écriture des systèmes dynamiques sous Scilab est assez simple. Pour implémenter notre système dynamique, nous allons tout d'abord définir une fonction récursive, dont la valeur à un temps donné dépend du temps t et de la valeur à t − 1. Par exemple, pour le système
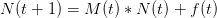
dans lequel la fonction parc(t,N) renvoie la valeur de N(t + 1), la fonction deff(...) servant à définir les fonctions sous Scilab.
Cette ligne sera déclinée en 5 versions, correspondant aux 5 classes technologiques considérées. Les 5 “sous-parcs” seront donc définis par les lignes suivantes :
Les sous-parcs que nous venons de définir font appel à différents paramètres qu'il nous faut à présent initialiser, à savoir :
N.B.:Toutes les données numériques de parc sont en milliers de véhicules
Nous avons les données chiffrées du parc automobile français entre 1962 et 1999, réparti en 36 classes d'âge.
Le fichier matA.dta contient la composition du parc automobile français total (donc sans tenir compte d'une quelconque séparation en classes technologiques). Pour charger les données sous Scilab, taper la commande
qui charge en mémoire une matrice A contenant les dites données. L'année 1999 nous servira de conditions initiales. Toutefois, la matrice A comporte en lignes les années de construction des véhicules en ordre croissant et en colonnes les années d'observation (de 1972 à 1999). L'année 1999 correspond donc à la dernière colonne, mais nous voulons les classes par âge croissant (et donc par année de construction décroissant), et seulement pour les 28 premières classes d'âge(contre 37 années de production dans la matrice A). D'où les commandes suivantes
Le vecteur N0 comporte alors la répartition du parc global en 28 classes d'âge en 1999. Il nous faut alors répartir ce parc en différentes classes technologiques. Ce que nous allons faire en définissant d'une part la proportion de diesels dans le parc, et en considérant d'autre part les proportions des différentes classes de cylindrée au sein de chaque type de motorisation (les prévisions étant présentées sous cette forme). Nous créons ainsi les paramètres pour le temps t = 0, c'est-à-dire en 1999 :
Puis nous choisissons les valeurs de ces mêmes paramètres pour les véhicules neufs en 2020 (t = 20), avant de procéder à une interpolation linéaire pour déterminer les valeurs des paramètres entre 1999 et 2020. C'est ici que nous pourrons faire varier le paramètre pd20 selon les prévisions de part du diesel3 . Nous considérerons par contre dans tous les cas que les diesels supérieurs représenteront 95% des immatriculations de diesels en 2020, et que les essences supérieures représenteront 55% des essences, les intermédiaires regroupant quant à elles 40% des essences.
Il y avait 2,2 millions d'immatriculations en 2000, et les prévisions sont de 2,5 millions d'immatriculations pour 2020. Bien évidemment, comme pour tous les paramètres de cette étude, on peut donner différentes valeurs aux immatriculations en 2020 pour tester diverses hypothèses, mais nous nous tiendrons au chiffre de 2,5 millions de nouveaux véhicules en 2020 cette simulation. Là encore, le nombre d'immatriculations pour les années intermédiaires est obtenu par interpolation linéaire entre 2000 et 2020. Et la ventilation des immatriculations dans les différentes classes technologiques se fait grâce aux coefficients annuels calculés au paragraphe précédent.
On peut se demander pourquoi mettre les immatriculations sous forme d'une matrice 28x21, alors que seule la première ligne est non nulle. Cela vient du fait qu'on ajoute les immatriculations au vecteur N à chaque pas de temps, donc les vecteurs doivent être de même taille, c'est-à-dire 28 lignes. Par ailleurs, chaque colonne représente un pas de temps, d'où les 21 colonnes.
La durée de simulation est implémentée par l'entremise d'un vecteur comportant toutes les valeurs prises par la variable de temps pendant la simulation. Ainsi, pour une simulation allant des années k = 2000 à k = 2020, on définit le vecteur temps t égal à 1 en 2000 :
Les coefficients de survie sont très importants, puisque ce sont eux qui permettent d'évaluer le nombre de véhicules passant d'une année à l'autre. Afin d'avoir une simulation pertinente, nous utiliserons donc les taux de survie réels observés en 1999 pour chaque classe technologique. Comme nous l'avons déjà signalé, ces taux seront pris constants tout au long de l'étude, tout en gardant à l'esprit que les parts des différentes classes technologiques varieront, et donc que les taux de survie globaux ne seront pas constants...
Pour charger en mémoire la matrice de survie, télécharger le fichier survie.dta et inclure dans notre fichier Scilab la commande suivante :
Cette matrice, dénommée survie, comporte les taux de survie de chaque tranche d'âge (les lignes de la matrice) dans chaque classe technologique (les colonnes). Nous allons donc extraire chaque colonne4 , puis la multiplier par un vecteur ligne 1x21, afin de copier cette colonne pour chaque pas de temps. On pourra ainsi modifier les taux de survie (en supposant par exemple que les véhicules sont plus fiables, ou au contraire qu'ils seront plus facilement mis à la casse). Nous nous contenterons toutefois ici de cette matrice aux colonnes identiques. Les lignes de commande sont donc :
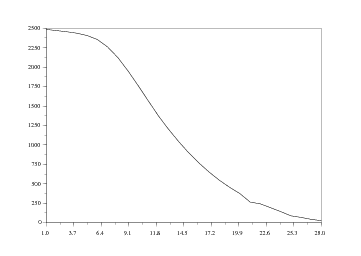
Le lecteur désireux de visualiser ces courbes de survie pourra taper des commandes telles que :
qui renvoie la courbe de la survie en fonction de l'âge du véhicule (en l'occurence ici pour les diesels supérieurs).
Enfin, il nous faut construire la fonction qui à chaque pas de temps extrait les coefficients de survie des matrices que nous venons de définir, et crée la matrice que nous avions appelé Mi :
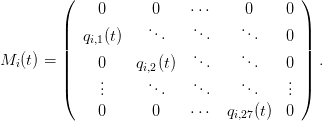 | (3) |
Cette disposition des coefficients est très facile à obtenir sous Scilab grâce à une macro qui prend comme argument un vecteur et crée une matrice nulle dont la diagonale est ledit vecteur, et décale cette diagonale si l'on ajoute un deuxième argument. D'où les lignes suivantes, que nous écrirons dans un fichier fonction.sci :
Il faut alors ajouter dans le fichier de commande une ligne pour charger ces fonctions :
Simulation de l'évolution du parc automobile
Nous avons défini notre parc automobile comme un système dynamique en temps discret. Nous allons donc utiliser un solveur d'équations différentielles pour calculer l'évolution du système. Ce solveur a pour nom ode et prend comme paramètres, dans l'ordre:
Nous allons utiliser ode pour chacune des classes technologiques, puis sommer les cinq classes pour obtenir le parc total. Ce qui donne au final les commandes suivantes:
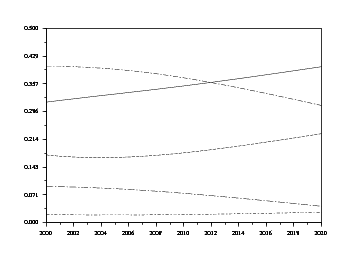
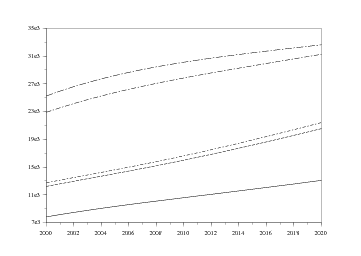
Maintenant que nous avons calculé l'évolution de chaque classe technologique, nous pouvons nous intéresser à la part de chacune dans le parc agrégé.
Nous allons donc définir les sommes des lignes des matrices d'évolution, afin d'avoir le nombre total de véhicules d'une classe technologique à un instant donné, sans se préoccuper des classes d'âge. Les lignes de commande sont assez intuitives :
On se reportera au chapitre suivant pour tout ce qui concerne la visualisation de ces résultats.
Visualisation des données
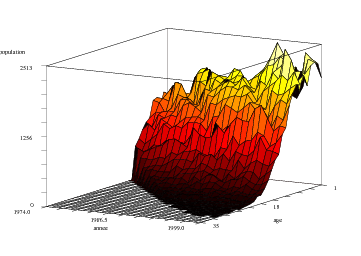
Nous avons au début de cette étude chargé en mémoire une matrice A (issue du fichier matA.dta) contenant la répartition en classes d'âge du parc global de 1962 à 1999.
Il suffit de taper la commande A pour que la matrice s'affiche à l'écran. Mais il est clairement plus agréable d'avoir une sortie graphique des données de cette matrice.
L'idée développée dans ce paragraphe va donc être de réaliser une représentation en trois dimensions, à savoir le nombre de véhicules en fonction d'une part de l'année d'observation, d'autre part de l'âge du véhicule. On pressent bien que la surface obtenue sera décroissante avec l'âge (les véhicules disparaissant année après année du parc), mais croissante avec l'année d'observation (les immatriculations augmentent d'année en année).
Avant toute chose, il faut taper les lignes suivantes qui définissent une palette de couleurs, pour un meilleur rendu des couleurs de la surface :
Ceci étant fait, il nous faut traiter les données de la matrice A. En particulier, nous allons supprimer la première ligne de la matrice, car elle contient le total des voitures construites avant 1962, et regroupe donc plus de voitures que les autres lignes (qui ne concernent qu'une seule année de construction chacune). La matrice obtenue comporte alors 35 lignes. La deuxième modification provient du fait que la matrice A est ordonnée par année de construction, alors que notre graphique sera en fonction de l'âge des véhicules. Nous créons donc une nouvelle matrice, B, de 35 lignes et 26 colonnes que l'on remplit en partant de la dernière ligne de A5 . Les commandes à taper sont regroupées ci-dessous :
Nous pouvons désormais taper la commande de représentation graphique en 3D. Il s'agit de la fonction plot3d. Pour simplifier, je vais donner la commande à taper, puis expliquer chacun des termes.
xbasc() efface les éventuels graphiques dans la fenêtre graphique. halt() permet de faire une pause dans le programme, pause qui prend fin si l'on appuie sur la touche “entrée”. Cette fonction évite ainsi que les différents graphiques s'enchaînent si l'on exécute le script6 . Les différents arguments de plot3d sont ici :
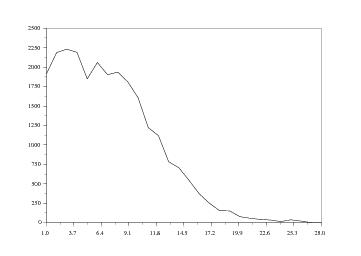
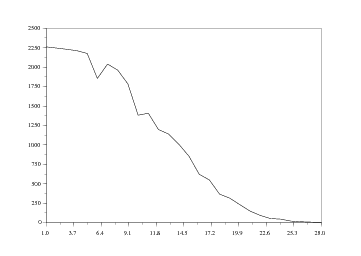
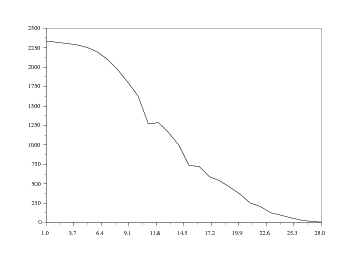
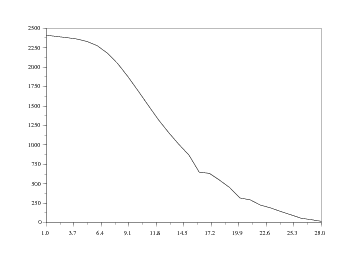
Si cette représentation est esthétiquement intéressante, elle soulève un problème assez gênant : elle n'est pas toujours facile à lire, les différentes cotes des points de la surface n'étant pas aisées à déterminer. Cette représentation permet plus de voir les mouvements d'ensemble que les données pour une année donnée.
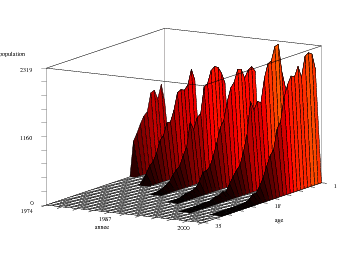
Pour pallier cette difficulté, nous allons utiliser parallèlement une autre représentation, se présentant sous forme d'ailerons. L'idée est ainsi de dessiner côte à côte les courbes en 2D du parc automobile pour des années données, par exemple tous les 5 ans. Pour ce faire, nous reprenons B et nous annulons quatre lignes sur cinq. Ce qui peut s'écrire :
La boucle for i=(1:5:26) permet d'attribuer à i les valeurs de 1 à 26 par pas de 5 (c'est-à-dire 1, 6, 11, etc...).
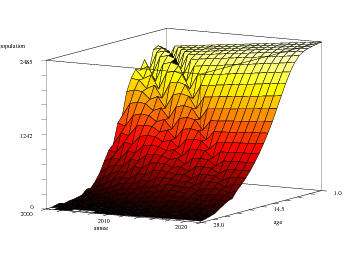
Visualiser le parc projeté ne pose pas de problème particulier dès lors que l'on a réussi à visualiser le parc passé.
Ainsi, au lieu de visualiser B, on visualise directement N, qui est, rappelons-le, la matrice contenant les effectifs de chaque année (colonnes), pour chaque classe d'âge (lignes).
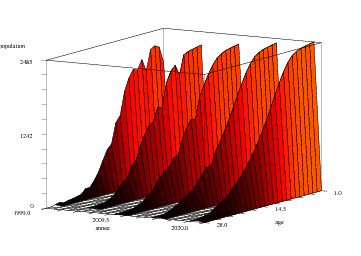
Quant au graphique par ailettes, on procède de la même manière que précédemment, c'est-à-dire en recopiant qu'une année (donc colonne) sur 5 parmi celles de N, et en rajoutant une dernière colonne nulle, pour que la dernière ailette soit complète7 .
Les lignes de commande sont finalement les suivantes :
Les paragraphes précédents permettent certes de réaliser de jolis graphiques, mais il peut être préférable de recourrir au “classique” graphique en deux dimensions, ne serait-ce que par souci de lisibilité, et pour tout simplement mettre l'accent sur un problème (et donc des courbes) que l'on juge important. Les paragraphes qui suivent ne traiteront donc plus que des graphiques en deux dimensions.
La première chose que nous allons donc faire est de lancer une nouvelle fenêtre graphique, ce qui permettra en outre de retrouver les couleurs d'origine dans cette fenêtre, alors que nous avons modifié la palette de la fenêtre pour les graphiques en 3D : en particulier, le tracé par défaut se fait en blanc sur fond blanc, ce qui est bien pour une surface de dégradés de couleurs (pour laquelle la lisibilité tient pour beaucoup aux dégradés dessinés) mais beaucoup moins pour une ligne monochrome, qui est alors confondu avec le fond... Bref, nous ouvrons une deuxième fenêtre, numérotée 1 (la première étant la 0) en tapant la commande :
Dans ce paragraphe, nous allons voir comment visualiser l'évolution du parc automobile autrement qu'avec des surfaces.
La simulation de l'évolution nous donne le parc pour chaque pas de temps, c'est-à-dire chaque année. Nous allons donc afficher l'une après l'autre chaque année : on visualisera ainsi la répartition du parc par tranches d'âge, d'abord pour la première année de simulation, puis pour la suivante, et ainsi de suite jusqu'à la dernière année :
Nous utilisons la commande plot2d, dont le rôle est de tracer des graphiques en 2D. Les différents paramètres sont grosso modo les mêmes que pour plot3d, l'argument [1,0,28,2500] que nous ajoutons ici étant en fait le domaine de visualisation, le rectangle dans lequel est tracée la courbe, ce qui correspond dans cet exemple à x = 1 à 28 et y = 0 à 2500. On pourra se reporter à l'aide en ligne pour plus de précisions.
Nous réalisons par ailleurs une boucle, qui parcourt les colonnes (donc les années) les unes après les autres. Cette boucle contient, en plus de la fonction de tracé, la fonction halt(), qui insère une pause (pour bien voir la courbe nouvellement tracée, sans quoi tout irait trop vite), ainsi que la fonction xbasc() qui efface la fenêtre graphique, les différentes figures étant superposées si l'on n'insère pas cette fonction dans la boucle.
Nous avons, dans le chapitre précédent, calculé les effectifs globaux de chaque classe technologique pour chaque année de simulation, afin d'observer l'évolution des parts des différentes classes technologiques dans le temps.
Il nous faut à présent tracer ces données.
On pourrait tout d'abord les tracer les unes après les autres dans une même fenêtre, et en superposition. On taperait alors les commandes suivantes, où l'on note que le troisième paramètre de la fonction plot2d change à chaque ligne : il s'agit de la couleur du trait...
Mais on peut aussi visualiser l'évolution de la répartition en classes technologiques en réalisant un graphique des parts cumulées. On part ainsi du tracé de la part des essences inférieures, puis on superpose celui des essences intermédiaires auxquelles on a ajouté les essences inférieures, et ainsi de suite jusqu'au diesel supérieures. Une telle représentation rend un peu plus difficile l'appréciation de l'évolution des parts de chaque classe, mais a l'avantage de refléter l'évolution en valeur absolue.
Pénétration des nouvelles normes sur les émissions Estimer la pénétration d'une nouvelle norme sur les émissions polluantes, ou tout simplement d'un nouveau matériel (pot catalytique, filtre à particules), c'est estimer l'évolution de la proportion de véhicules répondant à la norme, et ainsi estimer les effets de l'introduction d'une norme sur les émissions du parc automobile.
Pour estimer la pénétration d'une nouvelle norme ou d'un nouveau matériel dans le parc automobile, il suffit de simuler le parc constitué par les véhicules répondant à cette norme ou par les véhicules de ce nouveau type, et de procéder ensuite comme il a été fait pour étudier l'évolution de la part de chaque classe technologique. Ainsi, on recense chaque année le nombre total de voitures dans le parc “nouvelle norme” et on le compare au nombre total de voitures dans le parc global.
On peut ainsi étudier la pénétration d'une nouvelle norme selon le nombre d'immatriculations neuves projetées pour cette norme.
Les normes sur les émissions sont supposées être présentes sur tous les véhicules neufs l'année de la rentrée en vigueur du texte. On suppose par ailleurs qu'aucune voiture ne répond à la nouvelle norme au départ. Cette hypothèse nous fait donc partir d'un état initial nul. Ce n'est pas tant pour simplifier la problème que pour ne pas avoir à inventer des données initiales qui ne correspondent à rien. Le lecteur pourra toujours se reporter à la simulation des classes technologiques s'il désire compliquer la donne, en introduisant par exemple un taux d'équipement des véhicules neufs variable avec le temps.
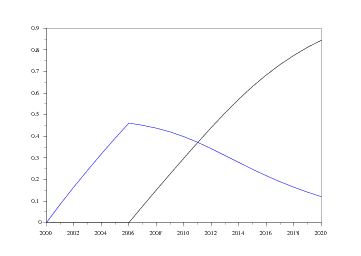
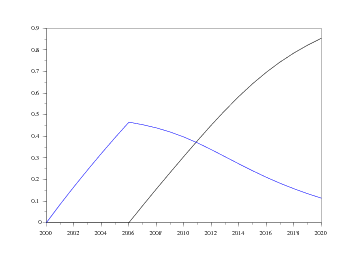
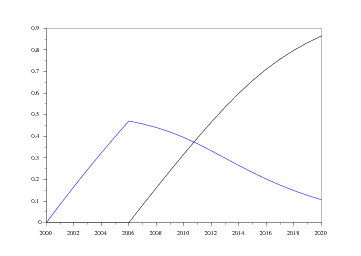
Nous allons en ce qui nous concerne tester les normes Proposal 2000 et Proposal 2010, chacune contenant dans sa dénomination son année d'entrée en vigueur, et la deuxième remplaçant la première (qui s'arrête donc en 2010). On peut ainsi voir le taux de pénétration selon l'évolution du nombre d'immatriculations, taux qui est bien évidemment d'autant plus élevé qu'il y a plus d'immatriculations neuves.
Nous introduisons donc de nouveaux sous-parcs, à savoir un par norme et par classe technologique. L'implémentation est ici aisée puisque la simplicité des conditions nous ramène à un simple décalage du temps initial à l'année de rentrée en vigueur de la nouvelle norme.
D'où les lignes suivantes, où l'on introduit au passage les parts des différentes normes dans le parc :
La visualisation est alors identique à celles déjà abordées :
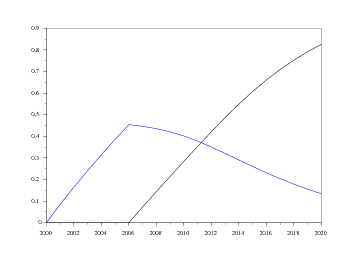
Les graphiques suivants montrent la vitesse de pénétration de ces deux normes selon le nombre d'immatriculations projeté en 2020. On notera tout de même que les courbes restent très proches l'une de l'autre8 .
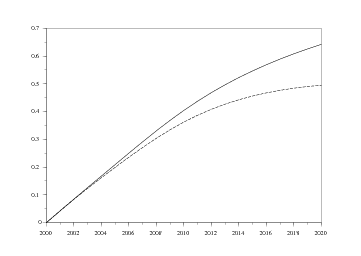
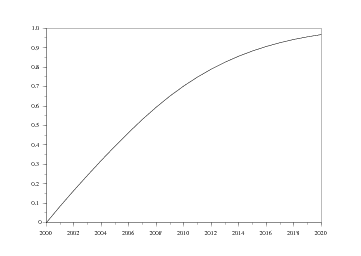
On peut également simuler la pénétration d'un équipement, comme par exemple le pot catalytique essence nouvelle génération, par rapport au nombre total de voitures en circulation et par rapport aux nombres de voitures essence en circulation, en supposant que toutes les nouvelles voitures essence le possèdent à partir de 2000. On obtient ainsi le graphique 16, correspondant aux scénarios bas et haut. Enfin, le dernier graphique [Fig 17] nous montre la pénétration d'une norme généralisée à tous les nouveaux véhicules (comme par exemple un pot catalytique essence ou diesel). Cela correspond donc à la pénétration des nouvelles générations par rapport au total du parc. On observe ainsi qu'au bout d'un an , plus de 8% du parc répond à la norme, mais que ce n'est qu'au bout de 16 ans que plus de 90% du parc est aux normes.
Le code source final Le code présenté dans cette partie reprend tous les morceaux disséminés au fil des explications dans les chapitres précédents. Il n'est donc pas “complet” en ceci qu'il faudrait le relancer plusieurs fois de suite en changeant les paramètres (part future des diesels, etc.) pour pouvoir faire des comparaisons intéressantes. L'objet de cet exposé étant l'utilisation de Scilab pour simuler l'évolution d'une population (ici, des automobiles), nous laisserons le soin au lecteur de poursuivre les essais de différents paramètres pour approfondir tout ce qui n'a pas trait directement à Scilab.
| L'École des Ponts ParisTech est membre fondateur de |
L'École des Ponts ParisTech est certifiée |
|
|
|



