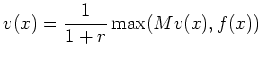|
Table des matières
1 Stoping time problem in infinite horizon
Let
![$\displaystyle v(x)=\sup_{\tau \mbox{s.t}} {\mathbb{E}} \left[ \frac{1}{(1+r)^{\tau+1}} f( X_\tau) \vert X_0=x \right].
$](img3.png)
In order to numerically solve such a problem we will use a value iteration method and a policy iteration method. we will use on of the two following routines to generate a stochastic matrix.
function M= Mtrans(n) M=rand(n,n); s=sum(M,'c'); M= M./(s*ones(1,n)); endfunction function M= Mprom(n,d) A= 2*diag(ones(1,n)) -diag(ones(1,n-1),1) -diag(ones(1,n-1),-1); A(1,2) = 2*A(1,2) ; A($,$-1)=2* A($,$-1); M = eye(A) - A*d endfunction
|