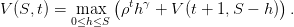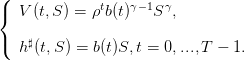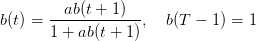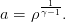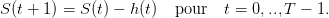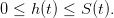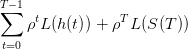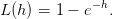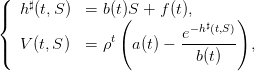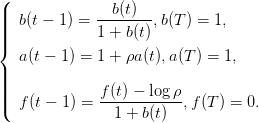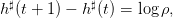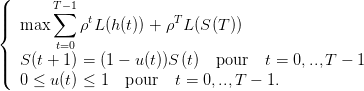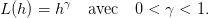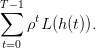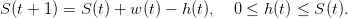On considère un planificateur souhaitant utiliser de manière optimale une ressource non
renouvelable (pétrole, minerai, etc.) sur T périodes. Le niveau de la ressource à l’instant t est le
stock S(t) et son prélèvement sur la période [t,t + 1[ est noté h(t), ce qui donne la dynamique
suivante :
(1)
On a
(2)
Le bien-être que le planificateur souhaite optimiser est représenté par la somme actualisée des
utilités de ses prélèvements successifs h(t) (supposés liés à la consommation par exemple) et du
stock final S(T)
(3)
où ρ ∈ [0, 1] est un facteur d’actualisation et L(.) une fonction d’utilité.
2 Cas déterministe : utilité de type exponentiel
On suppose que l’utilité est de type exponentiel
(4)
2.1 Résolution analytique par programmation dynamique
Question 1
Que vaut la fonction valeur à l’instant final V (T,S) ?
Quelle est la relation de récurrence liant les fonctions valeurs V (t − 1,.) et V (t,.)?
Montrer que, pour certaines valeurs de t et de S, le prélèvement optimal en boucle ferméeh♯(t,S) et la fonction valeur V (t,S) vérifient
(5)
où les paramètres a(t),b(t),f(t) sont définis par les récurrences
(6)
En déduire alors que les prélèvements optimaux en boucle fermée h♯(t) = h♯(t,S♯(t)) oùS♯(t + 1) = S♯(t) − h♯(t), satisfont la relation
(7)
et qu’ils sont donc décroissants dans le temps.
2.2 Programmation sous Scilab
Question 2Ouvrir un fichier nom_de_fichier.sce(par exemple, TP_renouv.sce) et yrecopier les paramètres suivants.
Y construire les vecteurs b et f donnés par l’équation (6), puis créer les vecteurs de stockset de prélèvements optimaux Sopt et hopt en utilisant la dynamique (1) et l’équation (5)du feedback.
Tracer trajectoire et décisions optimales en fonction du temps, à l’aide de la commandeScilabplot2d2.
//paramètres Horizon=4; //Horizon=40; S0=10; rho=0.8; // Construction de b et f b=[]; b(Horizon+1)=1; for t=Horizon:-1:1do b(t)=b(t+1)/(1+b(t+1)); end; f=[]; f(Horizon+1)=0; for t=Horizon:-1:1do f(t)=(f(t+1)-log(rho))/(1+b(t+1)); end; // Prélèvements et ressource optimales Sopt=[]; hopt=[]; Sopt(1)=S0; for t=1:Horizondo hopt(t)=b(t)*Sopt(t)+f(t); Sopt(t+1)=(Sopt(t)-hopt(t)); end, //vérification... //Sopt-[hopt ; Sopt($)] // Affichage xbasc(); plot2d2([0:(Horizon+1);0:(Horizon+1)]',[[hopt;Sopt($);0]';[Sopt;0]']', ... rect = [0,0,Horizon+2,Sopt(1)+1])
Question 3Répéter l’opération précédente pour différentes valeurs de l’horizon T.Commenter.
2.3 Résolution par dynoptim, routine d’optimisation dynamique
On introduit, pour des facilités de programmation, une nouvelle commande u ∈ [0, 1] telle que
h = uS. On considère alors le problème
(8)
comme un problème d’optimisation en la variable (S(0),...,S(T),u(0),...,u(T − 1)) ∈ ℝT+1× [0, 1]T
sous les contraintes d’égalité S(t + 1) = (1 − u(t))S(t) et d’inégalité 0 ≤ u(t) ≤ 1.
La macro dynoptim permet de traiter ce type de problèmes.
Question 4Charger dynoptim (menu toolboxes sous Scilab) et consulter le help. Définirla dynamique dyn et ses dérivées partielles dyn_Spar rapport à l’état S et dyn_upar rapportà la commande u. Faire de même avec le coût instantané et le coût final. Écrire les contraintessur les commandes.
//exec("/home/s/scilab-contrib/dynoptim-1.2/loader.sce"); //exec /usr/local/scilab-cvs/contrib/dynoptim/loader.sce help dynoptim //////////////////////// //dynamique //////////////////////// function z=dyn(u,S,t) z=S*(1-u),endfunction; function D=dyn_S(u,S,t) D=1-u,endfunction; function D=dyn_u(u,S,t) D=-S,endfunction; //////////////////////// // Fonction d'utilité //////////////////////// function z=Utilite(h) z=1-exp(-h),endfunction; function D=DUtilite(h) D=exp(-h),endfunction; //////////////////////// // cout instantané (à minimiser !) //////////////////////// function z=L(u,S,t) z=-(rho^t)*Utilite(u*S),endfunction; function D=L_S(u,S,t) D=-(rho^t)*DUtilite(u*S)*u,endfunction; function D=L_u(u,S,t) D=-(rho^t)*DUtilite(u*S)*S,endfunction; //////////////////////// // cout final (à minimiser !) //////////////////////// function z=g(S,t) z=-(rho^t)*Utilite(S),endfunction; function D=g_S(S,t) D=-(rho^t)*DUtilite(S),endfunction; //////////////////////// // contrainte controles //////////////////////// u_min=zeros(1,Horizon); u_max=ones(1,Horizon);
Question 5Choisir un niveau initial de ressource S0 et un horizon T. Initialiserl’algorithme d’optimisation dynamique dynoptim avec un vecteur u_init. Faire un appel àdynoptim et tracer les solutions. Vérifier dans quels cas les solutions coïncident avec cellesdes questions précédentes.
Question 6Que constatez-vous en faisant varier le facteur d’actualisation ρ ?
3 Cas déterministe : utilité de type puissance
On suppose que l’utilité est de type dit isoélastique :
(9)
On suppose aussi que le bien-être que le planificateur souhaite optimiser est représenté par la
somme actualisée des utilités de ses prélèvements successifs h(t)
(10)
3.1 Résolution analytique par programmation dynamique
Question 7
Montrer que l’équation de Bellman s’écrit, pour t = 0,...,T − 1,
(11)
Montrer, par récurrence, que le prélèvement optimal h♯(t,S) et la fonction valeur V (t,S)
satisfont
(12)
Montrer que l’équation de récurrence satisfaite par b(t) est
(13)
où
(14)
3.2 Résolution numérique par programmation dynamique
On restreint le modèle (1) aux états et aux commandes entiers : S(t) ∈ ℕ, h(t) ∈ ℕ.
On recopiera dans un fichier nom_de_fichier.sci (par exemple, TP_renouv.sci) la macro
Bell_stoch suivante qui résoud numériquement l’équation de la programmation dynamique pour
un problème de minimisation et non pas de maximisation comme ici. On la chargera sous
Scilab par l’instruction exec(’TP_renouv.sci’).
function [valeur,feedback]=Bell_stoch(matrice_transition,cout_instantane,cout_final) // MINIMISATION // algorithme de programmation dynamique stochastique // pour une chaîne de Markov sur \{1,2...,cardinal_etat\} // matrice_transition = listeà cardinal_commandeéléments // composée de matrices de dimension (cardinal_etat,cardinal_etat) // cout_instantane = listeà cardinal_commandeéléments // composée de matrices de dimension (cardinal_etat,horizon-1) // cout_final = vecteur de dimension (1,cardinal_etat) // valeur = fonction valeur de Bellman, // matrice de dimension (cardinal_etat,horizon) // feedback = commande en feedback sur l'état et le temps // matrice de dimension (cardinal_etat,horizon-1) ee=size(cout_instantane(1));cardinal_etat=ee(1); cardinal_commande=size(cout_instantane); hh=size(cout_instantane(1));horizon=1+hh(2); valeur=0*ones(cardinal_etat,horizon); // tableau ou l'on stocke la fonction de Bellman // valeur(:,t) est un vecteur // : représente ici le vecteur d'état valeur(:,horizon)=cout_final; // La fonction valeur au temps T est cout_final feedback=0*ones(cardinal_etat,horizon-1); // tableau ou l'on stocke le feedback u(x,t) // Calcul rétrograde de la fonction de Bellman et // de la commande optimaleà la date 'temp' par l'équation de Bellman // On calcule le coût pour la commande choisie connaissant la valeur de la // fonction coûtà la date suivante pour l'état obtenu for temp=horizon:-1:2do //équation rétrograde // (attention, pour des questions d'indices, bien finir en :2) loc=zeros(cardinal_etat,cardinal_commande); // variable locale contenant les valeurs de la fonction valeur de Bellman // loc est une matrice for j=1:cardinal_commandedo loc(:,j)=matrice_transition(j)*valeur(:,temp)+cout_instantane(j)(:,temp-1); end; [mm,jj]=mini(loc,'c') // mm est le minimum atteint // jj est la commande qui réalise le minimum valeur(:,temp-1)=mm; // coût optimal feedback(:,temp-1)=jj; // feedback optimal end endfunction
On recopiera également dans le même fichier la macro trajopt suivante qui calcule des
trajectoires optimales.
function z=trajopt(matrice_transition,feedback,cout_instantane,cout_final,etat_initial) // z est une liste : // z(1) est la trajectoire optimale obtenue partant de etat_initial // z(2) est la trajectoire correspondante des commandes optimales // z(3) est la trajectoire correspondante des coûts // etat_initial = un entier // pour le reste, voir la macro Bell_stoch ee=size(cout_instantane(1));cardinal_etat=ee(1); cardinal_commande=size(cout_instantane); hh=size(cout_instantane(1));horizon=1+hh(2); z=list(); x=etat_initial; u=[]; c=[]; for j=1:horizon-1do u=[u,feedback(x($),j)]; c=[c,c($)+cout_instantane(u($))(x($),j)]; mat_trans=full(matrice_transition(u($))); x=[x,grand(1,'markov',mat_trans,x($))]; end c=[c,c($)+cout_final(x($))]; z(1)=x;z(2)=u;z(3)=c; endfunction
Question 8Choisir des valeurs pour le stock initial, l’horizon, l’exposant de la fonctiond’utilité. Saisir la dynamique du système par le biais d’une matrice de transition, et saisirles coûts instantané et final. Tracer différentes trajectoires optimales.
exec('TP_renouv.sci') stacksize(10000000); S0=100; stock=0:S0; commande=0:S0; T=30; puis=0.5; rho=0.99; function y=cutoff(x,a) y=min(x,a)-a .*bool2s(x >a); endfunction cout_inst=list() for l=1:(S0+1)do // i.e. h=0,...,S0 cout_inst(l)=-(cutoff(l-1,(1:(S0+1))'-1))^puis*rho^(1:T); // si h=l-1 > S, le coût est nul // sinon h^puis end; cout_fin=zeros(1,S0+1)'; mat_trans=list() for l=1:(S0+1)do mat_trans(l)=zeros(S0+1,S0+1); // etats = stocks de 0à S0 for i=1:(S0+1)do mat_trans(l)(i,max(1,i-l+1))=1; // si h=l-1 > S, le coût est nul end; end; [valeur,feedback]=Bell_stoch(mat_trans,cout_inst,cout_fin); etat_initial=S0+1; zz=trajopt(mat_trans,feedback,cout_inst,cout_fin,etat_initial); // calcul des trajectoires optimales xset("window",1);xbasc(); plot2d2(1:prod(size(zz(1))),stock(zz(1)),rect = [0,0,T,S0]); xtitle("stock") xset("window",2);xbasc(); plot2d2(1:prod(size(zz(2))),commande(zz(2)),rect = [0,0,T,S0]); xtitle("commande") xset("window",3);xbasc();plot2d2(1:prod(size(zz(3))),-zz(3));xtitle("critère") // tracé des trajectoires optimales
4 Cas aléatoire
4.1 Modèle aléatoire
On suppose que de nouvelles ressources w(t) (éventuellement nulles) sont découvertes dans la
période [t,t + 1[, donnant
(15)
On suppose que w(0),...,w(T − 1) sont des variables aléatoires entières indépendantes et de même
loi.
4.2 Résolution numérique par programmation dynamique
Question 9Préciser les hypothèses mathématiques sous-jacentes au code Scilab suivant.Tracer différentes trajectoires optimales.
aleas=[0,10]; //probas=ones(aleas)/sum(ones(aleas)); probas=[0.9,0.1]; mat_trans=list() for l=1:(S0+1)do mat_trans(l)=zeros(S0+1,S0+1); // etats = stocks de 0à S0 for i=1:(S0+1)do for j=1:sum(ones(aleas))do mat_trans(l)(i,min(max(1,i-l+aleas(j)),S0+1))=mat_trans(l)(i, ... min(max(1,i-l+aleas(j)), ... S0+1))+probas(j); end; end; end; // vérification verif=0; for l=1:(S0+1)do verif=verif+abs(sum(sum(mat_trans(l),'c')-1)); end verif