
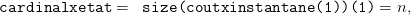
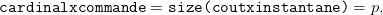
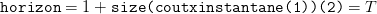
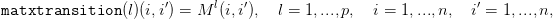
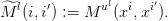
| L'École des Ponts ParisTech est membre fondateur de |
L'École des Ponts ParisTech est certifiée |



|
|


Le problème d’optimisation considéré ici est
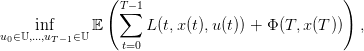 | (1) |
avec
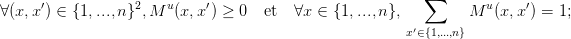
le terme Mu(x,x′) représente la probabilité que, partant de l’état x et appliquant la commande u à l’instant t, le futur état au temps t + 1 soit x′ :
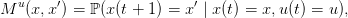
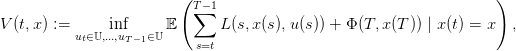 | (2) |
la fonction valeur évaluée sur l’état x à l’instant t,
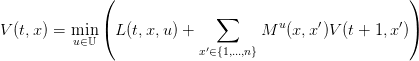 | (3) |
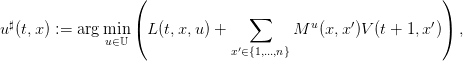 | (4) |
si l’inf est atteint en un unique argument,
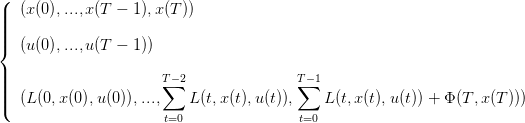 | (5) |
Le problème d’optimisation considéré ici identique avec
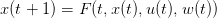 | (6) |
où w(0),…,w(T − 1) est une suite de variables aléatoires i.i.d.
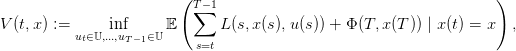 | (7) |
la fonction valeur évaluée sur l’état x à l’instant t, prise sur une loi produit ℙ sur 𝕎T ;
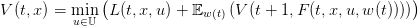 | (8) |
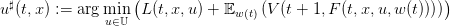 | (9) |
si l’inf est atteint en un unique argument,
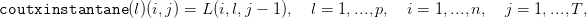 | (10) |
où on notera le décalage dans les indices temporels, et où
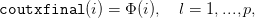 | (14) |
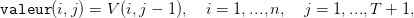 | (16) |
où on notera le décalage dans les indices temporels,
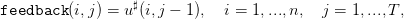 | (17) |
où on notera le décalage dans les indices temporels,
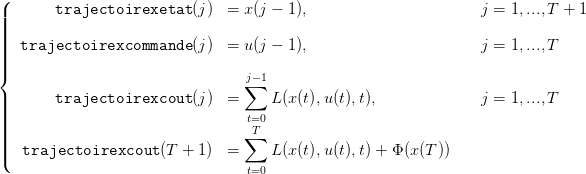 | (18) |
L’astuce employée ici consiste à utiliser un indice dans une matrice pour représenter l’état.
Le problème d’optimisation est toujours (1), mais avec
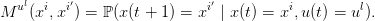 | (19) |
On se ramène au cas des entiers en introduisant
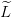 : {1,...,n}×{1,...,p}×{0,...,T − 1}→ ℝ, avec
: {1,...,n}×{1,...,p}×{0,...,T − 1}→ ℝ, avec
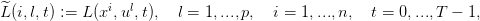 | (20) |
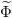 : {1,...,n}→ ℝ, avec
: {1,...,n}→ ℝ, avec
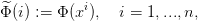 | (21) |
On transcrit ces données 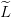 ,
, 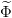 et
et 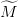 en objets Scilab cout_instantane, cout_final, matrice_trans.
L’exécution de la macro Bell_stoch retourne en particulier feedback.
en objets Scilab cout_instantane, cout_final, matrice_trans.
L’exécution de la macro Bell_stoch retourne en particulier feedback.
Pour la simulation de trajectoires optimales, il suffit alors d’introduire un vecteur etat de dimension (1,n) et tel que
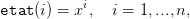 | (23) |
et un vecteur commande de dimension (1,p) et tel que
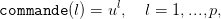 | (24) |
et d’exécuter une instruction du type
Les problèmes de discrétisation de l’espace d’état se posent assez naturellement quand le problème d’optimisation n’est pas formulé directement avec des matrices de transition, mais plutôt par le biais d’une fonction de dynamique. C’est ainsi qu’un problème d’optimisation déterministe est généralement formulé, mais aussi de nombreux problèmes d’optimisation stochastique.
Une dynamique commandée est une application
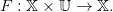 | (25) |
Une dynamique stochastique commandée est une application
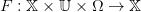 | (26) |
où 𝕏 est un espace mesurable, (Ω,μ) est un espace de probabilité, et où F(x,u,⋅) est supposée mesurable pour tous (x,u) ∈ 𝕏 × 𝕌.
Dans le cas où 𝕏 = {x1,...,xn} est un ensemble fini et où
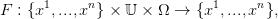 | (27) |
il est immédiat de définir une famille de matrices de transition sur 𝕏 = {x1,...,xn} par
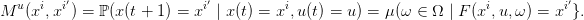 | (28) |
Nous supposons donnée une dynamique stochastique commandée
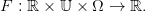 | (29) |
Nous discrétisons l’espace d’état ℝ en {x1,...,xn}, avec x1 <  < xn. Nous discrétisons
également l’espace de commande 𝕌 en {u1,...,ul}.
< xn. Nous discrétisons
également l’espace de commande 𝕌 en {u1,...,ul}.
Nous définissons les applications prédécesseur Π : ℝ →{x1,...,xn} et successeur Σ : ℝ →{x1,...,xn} par
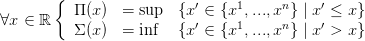 | (30) |
avec la convention que sup ∅ = x1 et inf ∅ = xn.
Nous allons distribuer aléatoirement tout x vers son prédécesseur et vers son successeur par la fonction ψ : ℝ × [0, 1] →{x1,...,xn} définie par
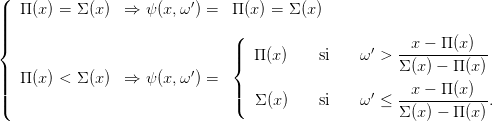 | (31) |
On discrétise alors la dynamique stochastique F par
![F^ : {x1,...,xn} × 𝕌 × (Ω × [0,1],μ ⊗ dω′) → {x1, ...,xn }](macros_pro_dyn39x.png) | (32) |
où
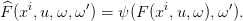 | (33) |
Nous reprenons ce qui est fait ci-dessus, mais avec F déterministe.
La dynamique commandée dynamique_commandee est transformée en une famille de matrices de transition discretisation(etat,commande,dynamique_commandee) : partant d’un état xi et appliquant la commande ul, on transite vers les deux voisins encadrant dynamique_commandee(xi,ul) (ou un seul si on est en deçà ou au delà de {x1,...,xn}) avec une probabilité égale à la distance normalisée à ces points (ou égale à 1).
La macro Scilab suivantepredec_succes utilise la fonction dsearch, pas forcément disponible sur les versions les plus anciennes de Scilab. En cas de problème, la remplacer par le code à télécharger ici.
On peut généraliser ce qui a été fait pour N = 1, en discrétisant ℝN sur une grille finie
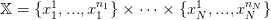 | (34) |
et en définissant des voisins 𝒱(x) ⊂ 𝕏 pour tout point x ∈ ℝN, avec des probabilités de transiter vers ces voisins.
On est alors ramené à une chaîne de Markov sur un espace fini 𝕏, qui a la particularité d’être un espace produit. Il reste alors à numéroter les éléments de 𝕏 pour se ramener à un problème d’optimisation stochastique sur des entiers.
Bien sûr, en terme de programmation informatique, ceci n’est pas si simple...
| L'École des Ponts ParisTech est membre fondateur de |
L'École des Ponts ParisTech est certifiée |
|
|
|



