
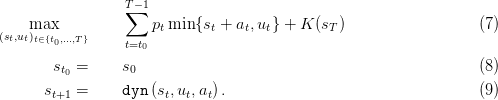
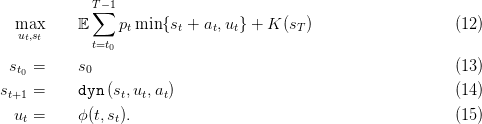
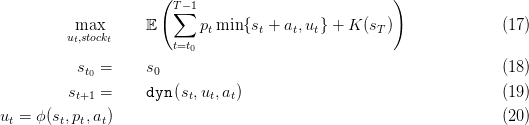
| L'École des Ponts ParisTech est membre fondateur de |
L'École des Ponts ParisTech est certifiée |



|
|


You will have to fill the following skeleton of scilab code during the practical course.
We consider a dam manager intenting to maximize the intertemporal payoff obtained by selling power produced by water releases.
Consider the dam dynamics st+1 = dyn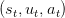 , where
, where
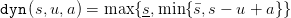 | (1) |
where
![𝕌 = [[0, ¯u]]](dam_management22x.png) (it can be seen as the period during which the turbine is open, and the
effective water release is min{st + at,ut}, necessarily less than the water st + at in the
dam at the moment of turbinating),
(it can be seen as the period during which the turbine is open, and the
effective water release is min{st + at,ut}, necessarily less than the water st + at in the
dam at the moment of turbinating),
We consider a problem of payoff maximization where turbining one unit of water has unitary price pt. On the period from t0 to T, the payoffs sum up to
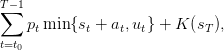 | (2) |
where K is the final valorization of the water in the dam.
Both the inflows at and the prices pt are uncertain variables. We denote by wt := (at,pt) the couple of uncertainties at time t. A scenario
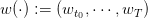 | (3) |
is a sequence of uncertainties, inflows and prices, from initial time t0 up to the horizon T.
A policy ϕ : [[t0,T − 1]] × 𝕊 → 𝕌 assigns a control 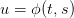 to any state s of dam stock volume
and to any time t ∈ [[t0,T − 1]].
to any state s of dam stock volume
and to any time t ∈ [[t0,T − 1]].
Given a policy ϕ and a scenario w(⋅) as in (3), we obtain a volume trajectory
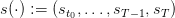 and a control trajectory
and a control trajectory 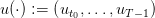 produced by the
“closed-loop” dynamics
produced by the
“closed-loop” dynamics
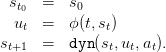 | (4) |
Pluging the trajectories 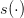 and
and 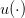 given by (4) in the criterion (2), we obtain the
evaluation
given by (4) in the criterion (2), we obtain the
evaluation
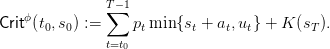 | (5) |
We consider a weekly management over a year, that is t0 = 0 and T = 52, with
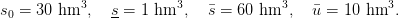 | (6) |
Prices and inflows data can be downloaded using the following html links:
We begin by generating a scenario of inflows and prices as follows.
Then, we are going to implement the code corresponding to §2.4 under the form of a macro simulation_det whose input arguments are a scenario and a policy (itself given under the form of a macro with two inputs and one output).
Question 2 Complete the Scilab macro simulation_det by implementing a time loop from initial time t0 up to the horizon T. Within this loop, follow the dynamics (4) and use formula (5) to compute the payoff. The outputs of this macro will be the gain (5) (scalar), and the state and control trajectories (vectors of sizes T − t0 + 1 and T − t0) given by (4).
This done, we are going to test the above macro simulation_det with simple strategies.
Question 3 Using the macro strat_constant, compute the payoff, the state and control
trajectories attached to the scenario generated in Question 1. Plot the evolution of the
stocks levels as a function of time. Design other policies, like, for instance, the constant
strategies (ut = k for k ∈ [[Dmin,Dmax]]) and the myopic strategy consisting in maximizing
the instantaneous profit 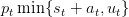 . Compare the payoffs given by those different
strategies.
. Compare the payoffs given by those different
strategies.
In a deterministic setting, we consider that the sequences of prices p(⋅) and inflows w(⋅) are known, and we optimize accordingly. The optimization problem we consider is
The theoretical Dynamic Programming equation is
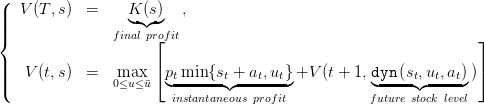 | (10) |
Here, we fix the final value K of water in problem (7) to 0. This means that the water remaining in the dam at time T presents no economic interest for the manager.
Question 4 Write the theoretical Dynamic Programming equation attached to Problem (7).
Then
What can you say about the level of water at the end of the period ? Can you explain ?
Question 5 Theoretically, what other mathematical methods could have been used to solve the dynamic optimization problem (7)?
We are optimizing the dam on one year. However at the end of this year the dam manager will still have to manage the dam, thus the more water in the dam at the end, the better for the next year. The question is how to determine this value.
The main idea is the following : we want to optimize the management of our dam on a very long time, however we would like to actually solve the problem only on the first year, representing the remainings years by the final value function K in (7). Thus K(s) should represent how much we are going to earn during the remaining time, starting at state s.
Question 6 Consider the optimal strategy sN∗ obtained when we solve problem (7) on N years, with zero final value (K = 0). Using the Dynamic Programming Principle find the theoretical function KN such that the restriction of the strategy sN∗ on the first year is optimal for the one year problem (Problem 7) with final value K = KN.
Thus, choosing the final value K = KN means that we take in consideration the gains on N years. We would like to have N going to infinity, however KN+1 − KN is more or less the gain during one year, thus KN will not converge. In the following question we will find a way of determining a final value converging with N that represents the problem on a long time.
Question 7 Consider the optimal control problem (7) with final value K, and the same problem with final value K + c, where c is a constant. What can you say about their optimal strategies ? their optimal values ?
If K is the value of remaining water, what should be the value of K(s) (in the sense that how much the future manager of the dam is ready to pay for you to keep the minimum water level in the dam) ?
How do you understand the macro final_value_det ? Test it and comment it. Plot the final value obtained as a function of the stock level.
For environemental and touristic reasons the level of water in the dam is constrained. We expect that, during the summer months (week 25 to 40), the level of water in the dam must be above a minimal level s′.
Question 8 Recall that a constraint can be integrated in the cost function : whenever the constraint is violated the cost function should be infinite.
Create a Scilab macro optim_det_constrained to integrate this constraint.
Compare the evolution (for different minimal levels s′) of stock trajectories and optimal values. What can you say about it ? What should you do in order to compute a final value of water adapted to the problem with constraints ?
A closed-loop strategy is a policy given by ϕ : [[t0,T − 1]] × 𝕊 → 𝕌, which assigns a water turbined
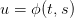 to any state s of dam stock volume and to any decision period t ∈ [[t0,T − 1]],
whereas an open-loop strategy is a predetermined planning of control, that is a function
ϕ : [[t0,T − 1]] → 𝕌.
to any state s of dam stock volume and to any decision period t ∈ [[t0,T − 1]],
whereas an open-loop strategy is a predetermined planning of control, that is a function
ϕ : [[t0,T − 1]] → 𝕌.
Let us note that, formally, an open-loop strategy is a closed-loop strategy.
Question 9 In a deterministic setting show that a closed-loop strategy is equivalent to an open-loop strategy in the sense that, for a given initial stock s0, the stock and control trajectories of (4) will be the same.
Write a Scilab macro that constructs an optimal open-loop strategy from the optimal closed-loop solution.
However, one can make an error in his prediction on inflows or prices and open-loop control may suffer from this. In order to represent this, we will proceed in the following way.
The “slight” modification of the original scenario must be simple and well understood. Thus we should change either the price or the inflow, at a few times only. However the size of the modification can be substantial.
Question 10 Write a Scilab macro comparison_openVSclosed_loop that will implement this procedure and test it. Are there any differencies of value and stock trajectories for the original scenario ? Are there any differencies of value and stock trajectories for the modified scenario ? Why ?
In the same macro, compute the optimal strategy for the modified scenario and compare the results of the open-loop and closed-loop strategies derived from the original scenario to the optimal result of the modified scenario.
Comment on the pro and cons of closed-loop strategies against open-loop strategies (in a deterministic setting).
In section 3 we have made optimization and simulation on a single scenario. However water inflows and prices are uncertain, and we will now take that into account.
We suppose that sequences of uncertainties 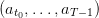 ,
, 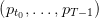 are discrete
random variables with known probability distribution. Moreover we will assume that a(⋅)
and p(⋅) are independent, and that each of them is a sequence of independent random
variables.
are discrete
random variables with known probability distribution. Moreover we will assume that a(⋅)
and p(⋅) are independent, and that each of them is a sequence of independent random
variables.
Notice that the random variables 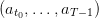 are independent, but that they are not
necessarily identically distributed. This allows us to account for seasonal effects (more rain in
autumn and winter).
are independent, but that they are not
necessarily identically distributed. This allows us to account for seasonal effects (more rain in
autumn and winter).
To each strategy ϕ, we associate the expected payoff
![ϕ T∑ −1
𝔼 [Crit (t0,s0)] = 𝔼 [ ptmin {st + at,ut} + K (sT )].
t=t0](dam_management220x.png) | (11) |
This expected payoff will be estimated by a Monte-Carlo approach. In order to do that we will
use the macros Price and Inflows that generate a table of random trajectories of the noise, each
line being one scenario. The expected payoff of one strategy will be estimated as the empirical
mean of the payoff on these scenarios. In order to compare two strategies we have to use the same
scenarios for the Monte-Carlo estimation. Thus, we fix a set of simulation scenarios (ωi)i∈[[1,n]],
where ωi = {p1i,a
1i, ,p
T i,a
T i}. and we will always evaluate the criterion 𝔼Critϕ as
,p
T i,a
T i}. and we will always evaluate the criterion 𝔼Critϕ as
 ∑
i=1NCritϕ(ω
i).
∑
i=1NCritϕ(ω
i).
Consequently the problem is now written as
Here, we will use the macros simulation and simulation_Bellman that simulate a strategy on each scenario giving a vector of gains, as well as a matrix of stock and control trajectories.
Question 11 As in Question 1, test the constant strategies and compare the results.
We have seen that, in the deterministic case (without any errors of prevision), an open-loop strategy is equivalent to a closed-loop strategy. Thus, in a probabilistic setting, one can be tempted to determine an optimal open-loop strategy.
In a first part, we will work on a mean scenario to derive an open-loop strategy.
Question 12 Complete the macro simu_mean_scenario, using the macros from the deterministic study, to compute the optimal strategy for the mean scenario.
In a second part we compute the best open-loop strategy using the function optim
built-in in Scilab. We choose a set of optimization scenarios (ω′i)i∈[[1,Nmc]], where
ω′i = {p′1i,a′
1i, ,p′
T i,a′
T i}. (let us note that this set of scenarios is fixed and that it is
different from the set of simulation scenarios). Then we construct a cost function J(u)
as
,p′
T i,a′
T i}. (let us note that this set of scenarios is fixed and that it is
different from the set of simulation scenarios). Then we construct a cost function J(u)
as
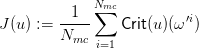
where u is a vector of T − 1 variables reprensenting the planning of control. Thus we have
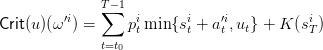
with
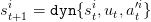
Question 13 Use the macro best_open_loop to obtain the best possible open-loop strategy. Test it and compare to the strategy obtained for the mean scenario. You will consider the simulation of both strategies on the optimization scenarios and on the simulation scenarios.1
We will now focus on finding an optimal closed loop solution for problem (12) The dynamic programming equation associated to the problem of maximizing the expected profits is
![(
|| V (T, s) = K-(s-) ,
{ fin◟a◝l◜ p◞rofit
||( V (t,s) = 0m≤aux≤ ¯u𝔼 [p◟tmin{st◝◜+-at,ut}◞+V (t + 1, d◟yn-(st◝,◜ut,at)◞)],
instantaneous profit future stock level](dam_management228x.png) | (16) |
Question 14 Complete the function DP, that solves the dynamic programming equation (We consider that K = 0).
Then write a macro simulation_Bellman_DH that will simulate the optimal strategy on a set of simulation scenario.
Plot an histogram of the payoffs and plot an evolution of the stocks level. Compare the gains obtained with this strategy to the open-loop strategy derived from the mean-scenario. You can also compare this strategy to the optimal open-loop strategy.
One may note that, in practice, the dam manager often assume that the weekly inflows and prices are perfectly known. Indeed at the beginning of the week meteorologists and economists can give some predictions. Moreover this problem is only an approximation of the real one, as a dam is managed per hour and not per week, thus the manager has more information than what we assume in a Decision-Hazard setting. Consequently we will now change slightly problem (12) by assuming that, at each time step t we know the price pt and inflow at.
Problem (12) is turned into
The choice of the probabilistic model of noises (prices and inflows) is quite important. Until now, we have represented the noises as independent variables, and this is not the more precise probabilistic model we could have used. Consequently we might want to estimate the potential gain in using a more precise (but numerically less tractable) probabilistic model. Thus we would like to have an upper bound on our problem. Such an upper bound can be found by doing an anticipative study : for each scenario we compute the best possible gains on this scenario.
Let us stress out that this will not give a strategy that can be used. It only gives an upper bound on the possible gain for a set of simulation scenario, a-posteriori.
Question 16 Write a macro Simu_anticipative, that computes for each scenario the upper bound given by the deterministic optimisation. Compare the results obtained by the differents strategies with this upper bound.
| L'École des Ponts ParisTech est membre fondateur de |
L'École des Ponts ParisTech est certifiée |
|
|
|



